
分布式锁简介
随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的Java API并不能提供分布式锁的能力。为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题。
分布式锁可以用来解决缓存击穿的问题,在大量请求访问某个可能会过期的 key 前,先加上分布式锁,这样就能保证数据库只会被访问一次,从而减轻了数据库的压力。
分布式锁主流的实现方案:
- 基于数据库实现分布式锁
- 基于缓存(Redis等,将key存储在缓存中)
- 基于 ZooKeeper(将key存储在ZooKeeper中)
每一种分布式锁解决方案都有各自的优缺点:
- 高性能:Redis(AP),但其无法保证主从机器上的缓存数据是一致的,可能主机刚保存了某个锁,还未同步给从机,自己就宕机了。在哨兵机制选举出了另一台主机后,其内并不存在该锁,故此前加的分布式锁失效,但其能保证高性能,而不像ZooKeeper一样主从同步时服务无法访问。
- 可靠性:ZooKeeper(CP),能够保证数据的一致性,主机收到的加锁消息会在同步给所有从机后再一起添加到缓存中,此时即可以保证分布式锁数据高度一致,但是缺点是同步期间服务无法访问,性能降低。
本文将介绍基于Redis的分布式锁实现方式。
阶段一:未加锁时
在未加锁时,不论是单机应用还是分布式应用,都会出现超卖问题,原因:
- 某个线程先进行get判断,发现库存有剩余,就准备执行减库存操作。
- 而在其减库存操作完成之前,另一个线程进行了get判断,也发现库存有剩余,此时该线程也会执行减库存操作,从而造成同一个商品被消费两次。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| @Autowired
private StringRedisTemplate stringRedisTemplate;
@GetMapping("/buy_goods")
public String buy_Goods(){
String result = stringRedisTemplate.opsForValue().get("goods:001");
int goodsNumber = result == null ? 0 : Integer.parseInt(result);
if(goodsNumber > 0){
int realNumber = goodsNumber - 1;
stringRedisTemplate.opsForValue().set("goods:001", String.valueOf(realNumber));
System.out.println("成功买到商品,库存还剩下: "+ realNumber + " 件" + "\t服务提供端口" + serverPort);
return "成功买到商品,库存还剩下:" + realNumber + " 件" + "\t服务提供端口" + serverPort;
}else{
System.out.println("商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort);
}
return "商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort;
}
|
版本二:单机版锁
使用 synchronized 关键字或 JUC 的 ReentraLock 类可实现单机版锁:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| class X {
private final ReentrantLock lock = new ReentrantLock();
public void m() {
lock.lock();
try {
} finally {
lock.unlock()
}
}
public void m2() {
if(lock.tryLock(timeout, unit)){
try {
} finally {
lock.unlock()
}
}else{
}
}
}
|
但其对分布式应用的超卖问题仍无法解决。
版本三: 分布式锁 SETNX
添加分布式锁的思路:
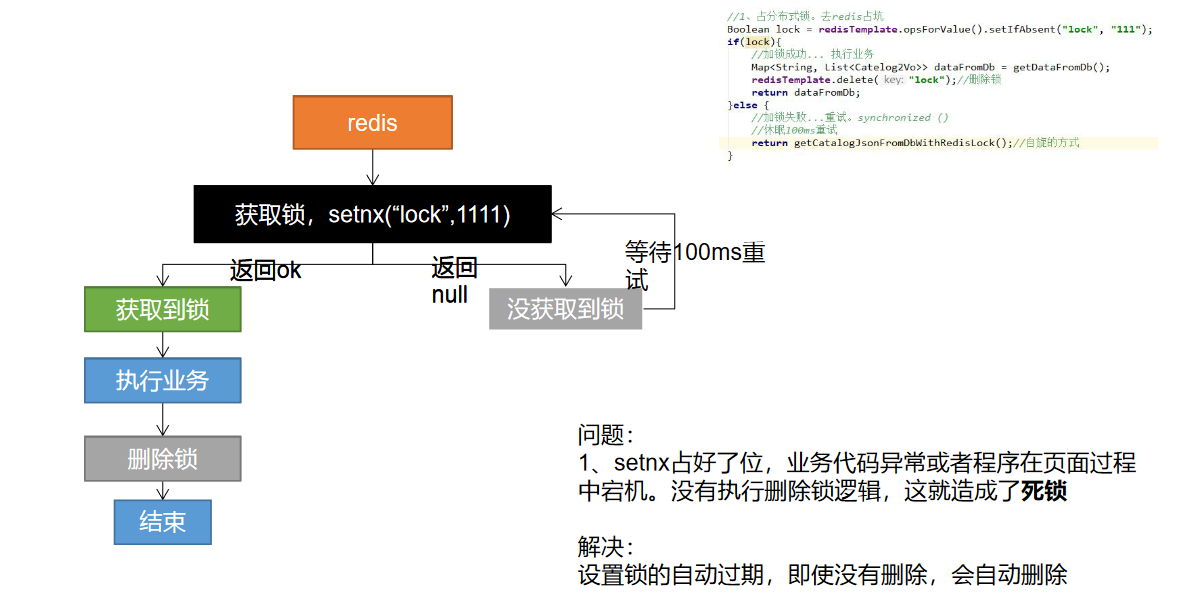
- 如果某个服务能获取到锁,就向 Redis 中添加一个
key = "lock",然后执行业务
- 此时其他服务再去 Redis 中查询 “lock” 是否存在时,就会发现锁已存在,就无法再占有锁,那么其就需要等待一定时间后循环尝试获取锁,直到获取到锁后才能执行业务
- 占有锁的服务在执行完业务后,需要释放掉锁
使用 Redis 提供的 SET 命令添加分布式锁:
1
| SET sku:1:info “OK” NX PX 10000
|
参数解读:
EX second :设置键的过期时间为 second 秒。 SET key value EX second 效果等同于 SETEX key second valuePX millisecond :设置键的过期时间为 millisecond 毫秒。 SET key value PX millisecond 效果等同于 PSETEX key millisecond valueNX :只在键不存在时,才对键进行设置操作。 SET key value NX 效果等同于 SETNX key valueXX :只在键已经存在时,才对键进行设置操作
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public static final String REDIS_LOCK = "redis_lock";
@Autowired
private StringRedisTemplate stringRedisTemplate;
public void m(){
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "0");
if (lock) {
Map<String,List<Catelog2Vo>> dataFromDb = getDataFromDB();
redisTemplate.delete("lock");
return dataFromDb;
} else {
System.out.println("获取分布式锁失败,等待重试");
try { TimeUnit.MILLISECONDS.sleep(200); } catch (InterruptedException e) { e.printStackTrace(); }
return getCatelogJsonFromDbWithRedisLock();
}
}
|
但此时仍然存在的问题:
- 当执行业务的过程中出现异常时,无法执行到释放锁的语句,那么锁就会一直存在,因此必须要在代码层面 finally 释放锁,保证业务出错时也能释放掉锁。
- 如果部署了微服务jar包的机器挂了,代码层面根本没有走到 finally 这块,那么这个key将永远不会被删除,同样没办法保证解锁,这时就出现了死锁情况。因此还需要给该锁设置一个过期时间限定key。
- 如果在添加锁后,设置过期时间前的某个时刻,服务宕机了,那么锁同样不会被添加过期时间,同样会出现死锁。
后两个问题出现的根本原因是,添加锁和设置过期时间的操作不是原子性的。为解决这三个问题,就需要:
- 添加 finally 块
- 给锁设置过期时间,并且必须和添加操作是原子性的
版本四:设置超时时间
使用 SET 命令时指定过期时间,同时保证加锁和设置超时时间是原子性的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public static final String REDIS_LOCK = "redis_lock";
@Autowired
private StringRedisTemplate stringRedisTemplate;
public void m(){
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "0", 300, TimeUnit.SECONDS);
if (lock) {
Map<String,List<Catelog2Vo>> dataFromDb = getDataFromDB();
redisTemplate.delete("lock");
return dataFromDb;
} else {
System.out.println("获取分布式锁失败,等待重试");
try { TimeUnit.MILLISECONDS.sleep(200); } catch (InterruptedException e) { e.printStackTrace(); }
return getCatelogJsonFromDbWithRedisLock();
}
}
|
另一个新问题:误删别人的锁。
可能第一个线程执行时间过长,在其删除自己上的锁之前,锁就已经过期了。此时再来一个线程上了锁,而第一个线程执行完业务后会删掉第二个线程上的锁:
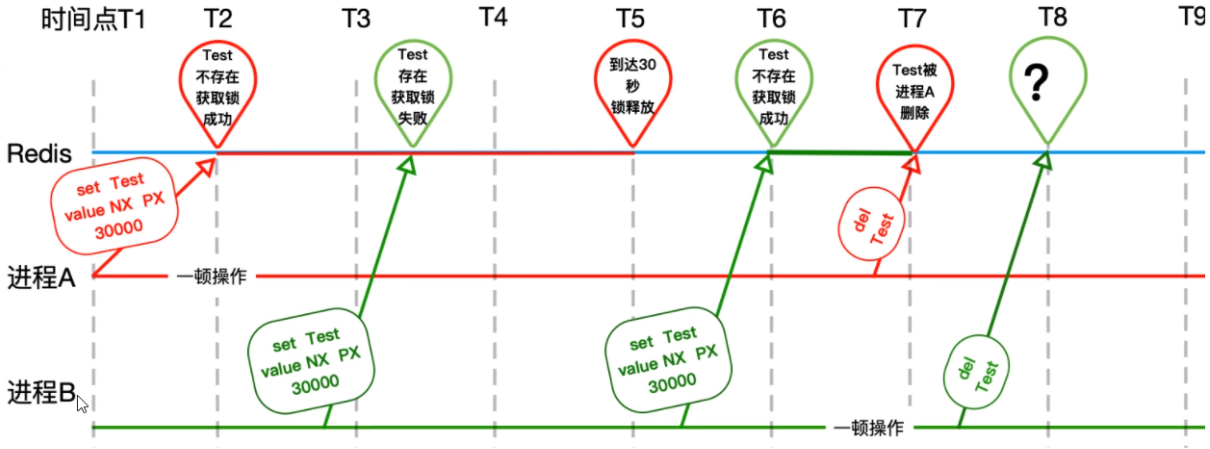
解决方法:给锁添加UUID,保证每个线程只能删除自己创建的锁。
版本五:添加 UUID 防止误删除
给每个线程创建独一无二的UUID,将其作为锁的value,防止误删。
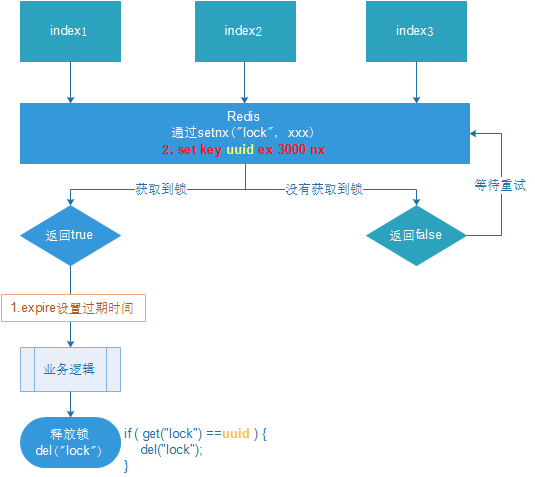
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| public static final String REDIS_LOCK = "redis_lock";
@Autowired
private StringRedisTemplate stringRedisTemplate;
public void m(){
String value = UUID.randomUUID().toString() + Thread.currentThread().getName();
try{
Boolean flag = stringRedisTemplate.opsForValue()
.setIfAbsent(REDIS_LOCK, value, 10L, TimeUnit.SECONDS);
if(!flag) {
return "抢锁失败";
}
} finally {
if(stringRedisTemplate.opsForValue().get(REDIS_LOCK).equals(value)) {
stringRedisTemplate.delete(REDIS_LOCK);
}
}
}
|
新的问题:finally 块里判断UUID是否和自己相等的代码和删除锁的代码不是原子性的,可能出现情况:
- 第一个线程在其加的锁即将结束前,查询到了该锁的value,并返回与自己本地存的UUID判断是否相等(对应上述 if 判断里的代码)
- 而第一个线程刚查询完,还没返回和自己本地存的UUID判断前,该锁过期了;
- 此时第二个线程创建了他自己的锁,其UUID显然与第一个线程本地存的UUID不同;
- 第一个线程此时再删除锁时,就会把第二个线程创建的锁删掉,仍然没解决误删除的问题
图解:
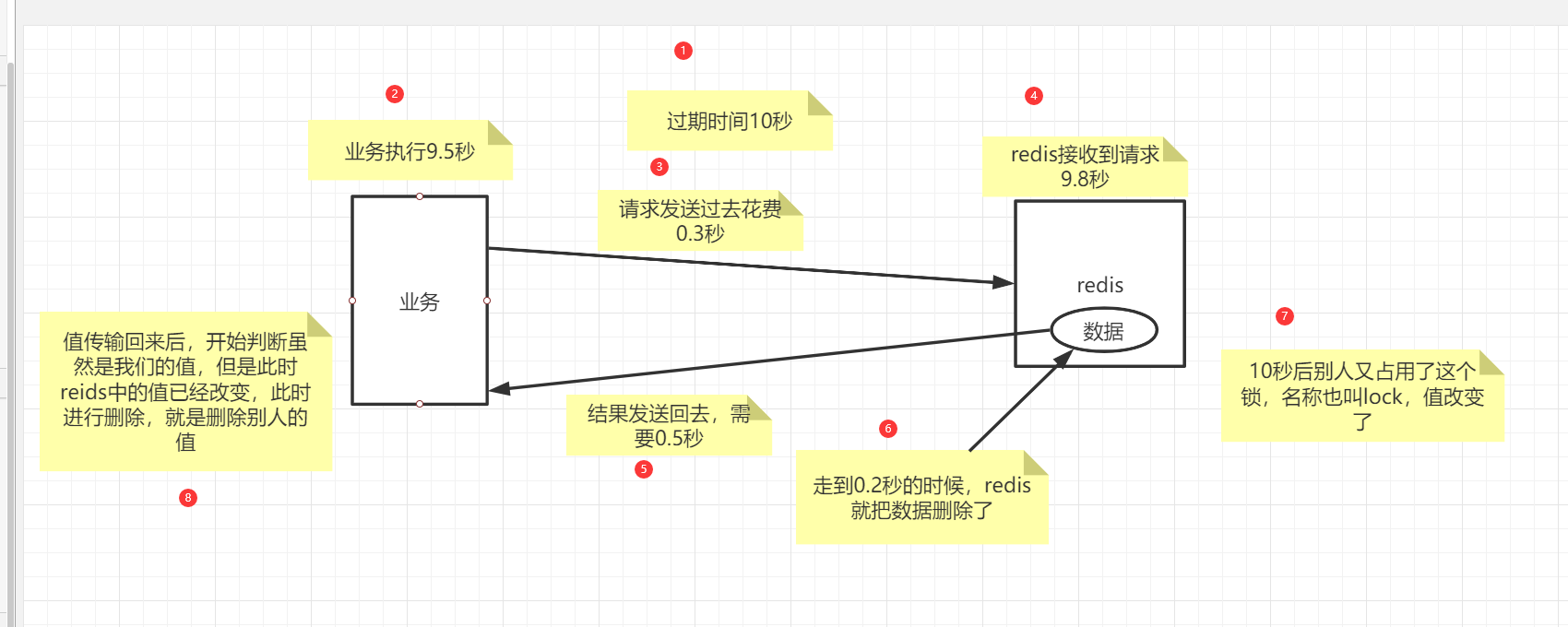
解决此问题的方法为:使用 LUA 脚本将判断与删除的操作变成原子性的。
版本六:LUA 脚本保证删除原子性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public static final String REDIS_LOCK = "redis_lock";
@Autowired
private StringRedisTemplate stringRedisTemplate;
public void m(){
String uuid = UUID.randomUUID().toString();
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);
if (lock) {
System.out.println("获取分布式锁成功");
Map<String,List<Catelog2Vo>> dataFromDb;
try {
dataFromDb = getDataFromDB();
} finally {
String script = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";
Long lock1 = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), Arrays.asList("lock"), uuid);
}
return dataFromDb;
} else {
System.out.println("获取分布式锁失败,等待重试");
try { TimeUnit.MILLISECONDS.sleep(200); } catch (InterruptedException e) { e.printStackTrace(); }
return getCatelogJsonFromDbWithRedisLock();
}
}
|
仍然存在的问题:我们自己设置的过期时间可能会在业务代码执行完毕前到期,不能做到自动续期,解决方法:
- 将过期时间调大,保证业务执行完毕前不会过期
- 使用 Redisson 中的 Reentrant Lock,利用其看门狗机制实现过期时间自动续期(推荐)
总结
目前分布式锁可能出现的解决问题通过以下方法解决:
setnx 保证加锁和设置过期时间的原子性(设置过期时间防止服务宕机后锁无法被删除)- Lua 脚本保证判断和解锁的原子性(锁的值设置为 UUID 防止误删别人的锁,因此才需要在删除前进行判断 value,等于自己的 UUID 才能删,并且解锁和判断必须保证原子性)
- 增加过期时间保证锁不会在业务执行完毕前过期
最终版本:使用 Redisson
Redisson 简介
关于 Redisson 的详细介绍见文章 【Redis】Redisson
官网文档上详细说明了不推荐使用 setnx 来实现分布式锁,应该参考 the Redlock algorithm 的实现

the Redlock algorithm:https://redis.io/topics/distlock
在 Java 语言环境下使用 Redisson,即 Redisson 是 Redlock 在 Java 中的实现。
官方文档:https://github.com/redisson/redisson/wiki/目录
Redisson是一个在 Redis 的基础上实现的 Java 驻内存数据网格(In-Memory Data Grid),提供了分布式和可扩展的 Java 数据结构。其特点:
- 基于 Netty 实现,采用非阻塞 IO,性能高
- 支持异步请求
- 支持连接池、pipeline、LUA Scripting、Redis Sentinel、Redis Cluster 不支持事务,官方建议以 LUA Scripting 代替事务
- 主从、哨兵、集群都支持。Spring 也可以配置和注入 RedissonClient。
- 实现分布式锁:在 Redisson 里面提供了更加简单的分布式锁的实现。
使用 Redisson
- 导入依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.0</version>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.12.0</version>
</dependency>
|
- 程序化配置:Redisson程序化的配置方法是通过构建
Config对象实例来实现的,使用Config对象创建出RedissonClient对象,后续所有对Redisson的使用都借助于RedissonClient对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| @Configuration
public static class MyRedissonConfig {
@Bean(destroyMethod="shutdown")
public RedissonClient redisson() throws IOException {
Config config = new Config();
config.useClusterServers()
.setPassword("zhaoyuyun")
.addNodeAddress("redis://127.0.0.1:7004", "redis://127.0.0.1:7001");
return Redisson.create(config);
}
@Bean(destroyMethod="shutdown")
public RedissonClient redisson() throws IOException {
Config config = new Config();
config.useSingleServer()
.setPassword("zhaoyuyun")
.setAddress("redis://myredisserver:6379");
return Redisson.create(config);
}
}
|
最终版本将使用RedissonClient操作分布式锁。思路:
- 先查看缓存中是否有该数据,如果有就返回
- 如果没有,先加分布式锁,然后再去数据库里查数据。而不应该先加锁再查缓存
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
@Override
public Map<String, List<Catalog2Vo>> getCatalogJsonWithRedis() {
String cache = redisTemplate.opsForValue().get("catalogJSON");
if (StringUtils.isEmpty(cache)) {
Map<String, List<Catalog2Vo>> catalogJson = getCatalogJsonFromDBWithRedissonLock();
String s = JSON.toJSONString(catalogJson);
redisTemplate.opsForValue().set("catalogJSON", s);
return catalogJson;
}
Map<String, List<Catalog2Vo>> result = JSON.parseObject(cache, new TypeReference<Map<String, List<Catalog2Vo>>>() {
});
return result;
}
public Map<String, List<Catalog2Vo>> getCatalogJsonFromDBWithRedissonLock() {
RLock lock = redissonClient.getLock("catalogJson-lock");
lock.lock();
Map<String, List<Catalog2Vo>> catalogJsonFromDB;
try {
catalogJsonFromDB = getCatalogJsonFromDB();
} finally {
lock.unlock();
}
return catalogJsonFromDB;
}
|
下面介绍一下 Redisson 中可重入锁的自动续期原理。关于 Redisson 中其他锁的详细介绍见文章 【Redis】Redisson
Redisson 可重入锁
基于Redis的Redisson分布式可重入锁RLock 。其实现了java.util.concurrent.locks.Lock接口。同时还提供了异步(Async)、反射式(Reactive)和RxJava2标准的接口。
该类可实现分布式锁的效果,原理为:在Redis缓存创建了一把锁,其他线程再想获取锁时就得阻塞等待该锁从Redis缓存中删除(底层有一个while(true)循环不断尝试获取锁)。
方式一:手动设置过期时间
1
| lock.lock(10, TimeUnit.SECONDS);
|
上述代码设置10s后自动解锁(不会自动续期),这个时间一定要大于业务的执行时间,否则锁过期后再unlock(),解锁的就是别的线程加的锁,此时就会报错uuid不匹配。
方式二:看门狗 + 自动续期
不手动指定过期时间,使用看门狗默认的过期时间 + 自动续期策略:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
RLock lock = redisson.getLock("myLock");
lock.lock();
try {
} finally {
lock.unlock();
if (lock.isLocked() && lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
|
流程:
- 当前线程在执行
lock() 后,将在Redis缓存中创建一个锁(Hash结构),其key值为"myLock",其内存储了key = uuid:线程号, value = 1,代表当前线程对象拥有了该锁;
- 此时其他线程再调用
lock() 时将发现Redis缓存中已经存在了"myLock"锁,因此会阻塞等待(while(true)循环判断锁是否还在);
- 等待当前线程调用
unlock() 后,该"myLock"锁将从Redis缓存中移除,此时其他线程才可以结束阻塞,创建另一把锁,即再在Redis缓存中创建一个"myLock" 。
上述方式的细节:
- 锁的自动续期:如果业务超长,运行期间自动会给锁续期到30s,不用担心业务时间长,锁自动过期被删掉。
- 加锁的业务只要运行完成,就不会给当前锁续期,即使不手动解锁,锁也默认也会在30s后自动删除。
自动续期原理:
- 如果我们给锁指定了超时时间,Redisson就会给Redis发送LUA脚本进行占锁且设置指定的超时时间(保证占锁和设置超时时间的原子性)
- 如果我们未指定锁的超时时间,Redisson就会设置超时时间为LockWatchdogTimeout(看门狗)的默认时间30s。如果占锁成功,就会返回一个
RFuture<Long> 对象,异步监听一个定时任务(用于给锁重新设置超时时间,新的超时时间就是看门狗的默认时间30s),之后每隔10s(三分之一的看门狗默认时间)就会将超时时间续期到30s
最佳实战:使用 lock.lock(30, TimeUnit.SECONDS) 方式并手动解锁。将超时时间设置的大一些,手动解锁。这样的好处是省掉了频繁续期的操作。
方式三:尝试加锁
尝试加锁,等待一定时间还未拿到锁就放弃加锁。
lock() 方法会阻塞等待直到获取到锁。若不想阻塞等待,可以使用tryLock() 方法,其会阻塞等待一定时间后停止等待,即放弃尝试加锁(和 JUC 中的 ReentrantLock 类似):
1
2
3
4
5
6
7
8
9
|
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}
|