publicstaticvoidmain(String[] args){ AtomicInteger i = new AtomicInteger(0); // 获取并自增(i = 0, 结果 i = 1, 返回 0),类似于 i++ System.out.println(i.getAndIncrement()); // 自增并获取(i = 1, 结果 i = 2, 返回 2),类似于 ++i System.out.println(i.incrementAndGet()); // 自减并获取(i = 2, 结果 i = 1, 返回 1),类似于 --i System.out.println(i.decrementAndGet()); // 获取并自减(i = 1, 结果 i = 0, 返回 1),类似于 i-- System.out.println(i.getAndDecrement()); // 获取并加值(i = 0, 结果 i = 5, 返回 0) System.out.println(i.getAndAdd(5)); // 加值并获取(i = 5, 结果 i = 0, 返回 0) System.out.println(i.addAndGet(-5)); // 获取并更新(i = 0, p 为 i 的当前值, 结果 i = -2, 返回 0) // 函数式编程接口,其中函数中的操作能保证原子,但函数需要无副作用 System.out.println(i.getAndUpdate(p -> p - 2)); // 更新并获取(i = -2, p 为 i 的当前值, 结果 i = 0, 返回 0) // 函数式编程接口,其中函数中的操作能保证原子,但函数需要无副作用 System.out.println(i.updateAndGet(p -> p + 2)); // 获取并计算(i = 0, p 为 i 的当前值, x 为参数1, 结果 i = 10, 返回 0) // 函数式编程接口,其中函数中的操作能保证原子,但函数需要无副作用 // getAndUpdate 如果在 lambda 中引用了外部的局部变量,要保证该局部变量是 final 的 // getAndAccumulate 可以通过 参数1 来引用外部的局部变量,但因为其不在 lambda 中因此不必是 final System.out.println(i.getAndAccumulate(10, (p, x) -> p + x)); // 计算并获取(i = 10, p 为 i 的当前值, x 为参数1值, 结果 i = 0, 返回 0) // 函数式编程接口,其中函数中的操作能保证原子,但函数需要无副作用 System.out.println(i.accumulateAndGet(-10, (p, x) -> p + x)); }
原子整型类AtomicInteger类的方法底层即使用了CAS思想:
1 2 3 4 5 6 7 8
publicclassCASDemo{ publicstaticvoidmain(String[] args){ AtomicInteger atomicInteger = new AtomicInteger(5); System.out.println(atomicInteger.compareAndSet(5, 2019)+"\t current data : "+ atomicInteger.get()); //修改失败 System.out.println(atomicInteger.compareAndSet(5, 1024)+"\t current data : "+ atomicInteger.get()); } }
privatevolatileint value; /** * Creates a new AtomicInteger with the given initial value. * * @param initialValue the initial value */ publicAtomicInteger(int initialValue){ value = initialValue; }
/** * Creates a new AtomicInteger with initial value {@code 0}. */ publicAtomicInteger(){ } ... /** * Atomically increments by one the current value. * * @return the previous value */ publicfinalintgetAndIncrement(){ return unsafe.getAndAddInt(this, valueOffset, 1); } ... }
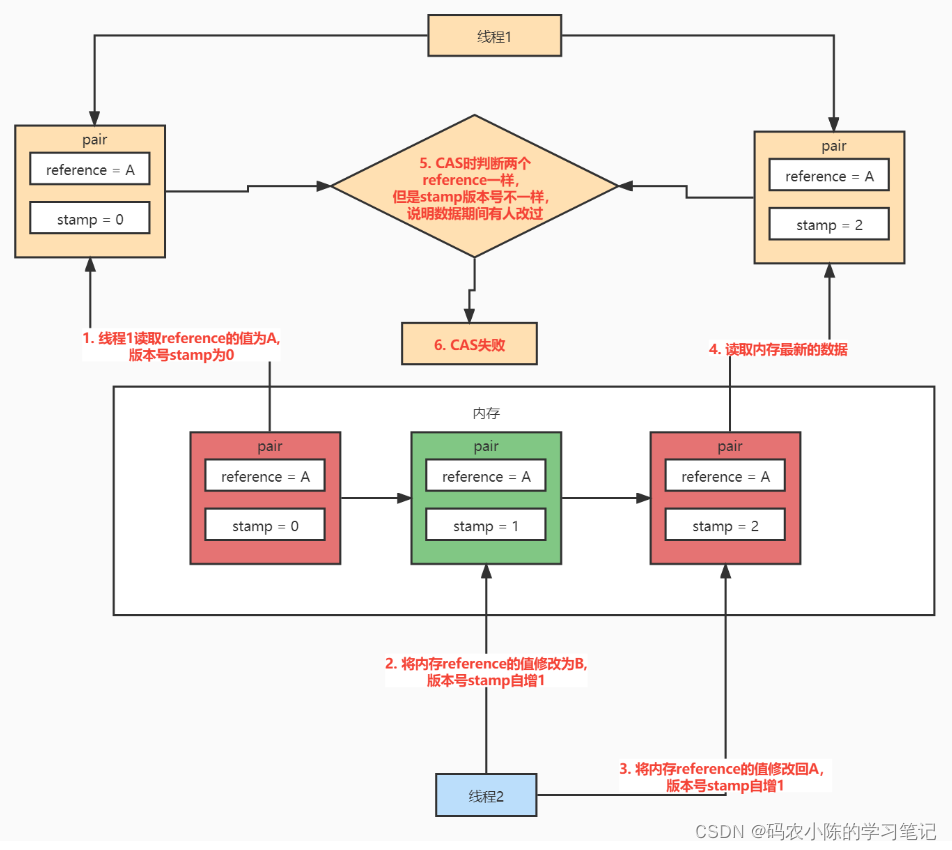
AtomicStampedReference 可以给原子引用加上版本号,追踪原子引用整个的变化过程,如:A -> B -> A ->C,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了几次。但是有时候,并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了AtomicMarkableReference。
publicstaticvoidmain(String[] args){ for (int i = 0; i < 5; i++) { demo(() -> new LongAdder(), adder -> adder.increment()); } for (int i = 0; i < 5; i++) { demo(() -> new AtomicLong(), adder -> adder.getAndIncrement()); }
}
privatestatic <T> voiddemo(Supplier<T> adderSupplier, Consumer<T> action){ T adder = adderSupplier.get(); long start = System.nanoTime(); List<Thread> ts = new ArrayList<>(); // 4 个线程,每人累加 50 万 for (int i = 0; i < 40; i++) { ts.add(new Thread(() -> { for (int j = 0; j < 500000; j++) { action.accept(adder); } })); } ts.forEach(t -> t.start()); ts.forEach(t -> { try { t.join(); } catch (InterruptedException e) { e.printStackTrace(); } }); long end = System.nanoTime(); System.out.println(adder + " cost:" + (end - start)/1000_000); }