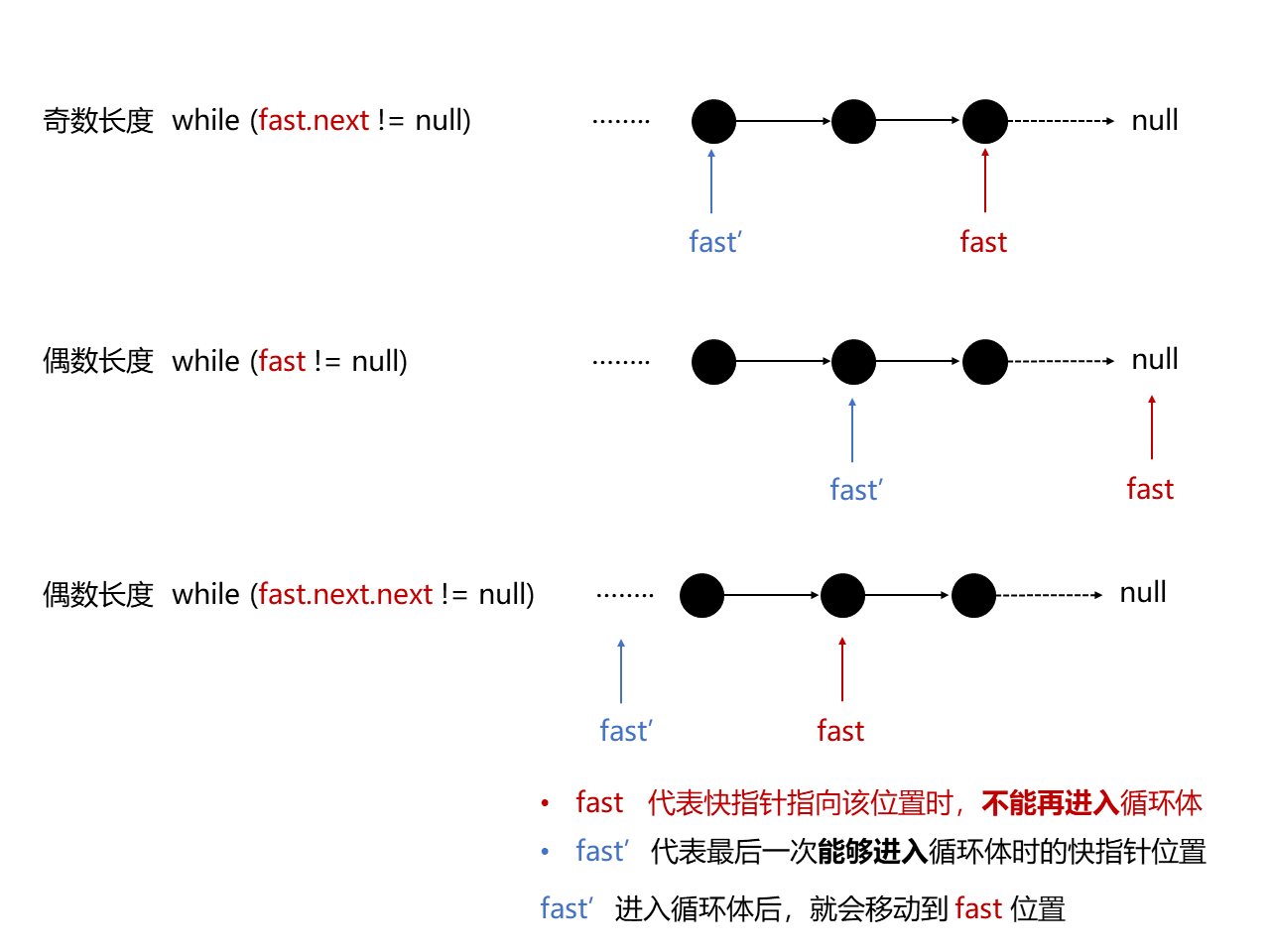
注意:绝对不能只写 while (fast.next != null),因为这样奇数长度虽然正常,但是偶数长度的最后一次 fast 将指向倒数第二个节点,这时while判断是成立的,还会进入循环中,但这样在其内进行 fast = fast.next.next; 操作时就会报 NullPointerException。
fast.next.next != null 的终止条件和 fast.next != null 的终止条件对于奇数长度的链表肯定是同时满足的,这是因为其奇数长度的特性,但对于偶数长度的链表并不是同时满足的。因为当偶数长度时,最后一次 fast 将指向倒数第二个节点,这时如果不加 fast.next.next != null 判断的话,还会进入循环中,这样在其内进行 fast = fast.next.next; 操作时就会报 NullPointerException
List<Integer> list = new ArrayList<>(); reverse(head, list); int[] ans = newint[list.size()]; for (int i = 0; i < list.size(); i++) { ans[i] = list.get(i); } return ans; }
public ListNode removeNthFromEnd(ListNode head, int n){ ListNode fast = head; ListNode slow = head; // fast移n步, for (int i = 0; i < n; i++) { fast = fast.next; }
// 如果fast为空,表示删除的是头结点 if (fast == null) return head.next;
while (fast.next != null) { fast = fast.next; slow = slow.next; }
publicstaticvoidmain(String[] args){ ListNode head1 = new ListNode(7); head1.next = new ListNode(9); head1.next.next = new ListNode(1); head1.next.next.next = new ListNode(8); head1.next.next.next.next = new ListNode(5); head1.next.next.next.next.next = new ListNode(2); head1.next.next.next.next.next.next = new ListNode(5); printLinkedList(head1); listPartition1(head1, 5); }
// 方式二:使用六个指针,分为三组:小于区域两个指针,等于区域两个指针,大于区域两个指针 publicstatic ListNode listPartition2(ListNode head, int pivot){ ListNode sH = null; // small head ListNode sT = null; // small tail ListNode eH = null; // equal head ListNode eT = null; // equal tail ListNode bH = null; // big head ListNode bT = null; // big tail
ListNode next = null; // save next node
// 遍历一次链表,将整个链表拆成三个区域,尾指针不断更新,头指针保持不动 while (head != null) { // 注意:需要将当前节点与原先链表断开连接 // 如果不断开的话,每个区域的尾结点都不是null,而是可能会连着其他节点 // 这样再串起来时就不对了,因此必须要在分区前先断开连接 next = head.next; head.next = null;
if (head.val < pivot) { if (sH == null) { sH = head; sT = head; } else { sT.next = head; sT = head; } } elseif (head.val > pivot) { if (bH == null) { bH = head; bT = head; } else { bT.next = head; bT = head; } } else { if (eH == null) { eH = head; eT = head; } else { eT.next = head; eT = head; } } head = next; }
// 如果上面不断开连接,这里就必须得手动断开,但是这样还必须保证 sT eT bT 不为空 // sT.next = null; // eT.next = null; // bT.next = null;
// 将三个区域的子链表进行合并 // 下面两个判断是交叉合并的,先合并小于区域和等于区域,再合并等于区域和大于区域 // 可以看到等于区域是重叠的,因为小于区域和大于区域都需要和等于区域进行连接 // 所以,分两步进行连接,先连接小于区域和等于区域,再将二者连接后的结果与大于区域连接 // small and equal reconnect if (sT != null) { sT.next = eH; // 这一步的目的是,如果等与区域为空,则将 eT 指向 sT // 这样在下一步连接大于区域时,如果等于区域为空则直接将大于区域连在小于区域后面 eT = eT == null ? sT : eT; } // all reconnect if (eT != null) { eT.next = bH; }
// 返回头结点时,将三个区域的头结点中第一个不为空的返回 return sH != null ? sH : eH != null ? eH : bH; }
publicstaticvoidmain(String[] args){ // 1->2->3->4->5->6->7->null ListNode head1 = new ListNode(1); head1.next = new ListNode(2); head1.next.next = new ListNode(3); head1.next.next.next = new ListNode(4); head1.next.next.next.next = new ListNode(5); head1.next.next.next.next.next = new ListNode(6); head1.next.next.next.next.next.next = new ListNode(7);
// 0->9->8->6->7->null ListNode head2 = new ListNode(0); head2.next = new ListNode(9); head2.next.next = new ListNode(8); head2.next.next.next = head1.next.next.next.next.next; // 8->6 System.out.println(getIntersectNode(head1, head2).val);
// 1->2->3->4->5->6->7->4... head1 = new ListNode(1); head1.next = new ListNode(2); head1.next.next = new ListNode(3); head1.next.next.next = new ListNode(4); head1.next.next.next.next = new ListNode(5); head1.next.next.next.next.next = new ListNode(6); head1.next.next.next.next.next.next = new ListNode(7); head1.next.next.next.next.next.next = head1.next.next.next; // 7->4
// 0->9->8->2... head2 = new ListNode(0); head2.next = new ListNode(9); head2.next.next = new ListNode(8); head2.next.next.next = head1.next; // 8->2 System.out.println(getIntersectNode(head1, head2).val);
// 0->9->8->6->4->5->6.. head2 = new ListNode(0); head2.next = new ListNode(9); head2.next.next = new ListNode(8); head2.next.next.next = head1.next.next.next.next.next; // 8->6 System.out.println(getIntersectNode(head1, head2).val); } }
删除排序链表中的重复元素 II
82. 删除排序链表中的重复元素 II:给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
思路:使用两个指针 cur 和 pre 一起右移
首先进行 while 循环,一直进行到 cur 和 cur.next 的值不相等,代表其后不存在与之重复的节点
public ListNode deleteDuplicates(ListNode head){ if (head == null) { returnnull; } ListNode dummy = new ListNode(-1); ListNode newcur = dummy; ListNode cur = head; ListNode pre = dummy;
while (cur != null) { // 1. 保证退出循环的 cur 和 cur.next 是不重复的 while (cur.next != null && cur.val == cur.next.val) { pre = cur; cur = cur.next; }
// 2. 出循环时,cur 肯定和 cur.next 不相同,此时判断一下 pre 和 cur 是否相同 if (pre.val == cur.val && pre != dummy) { // 如果相等,就是重复的节点,不保存该节点,开始下一个节点 cur = cur.next; } else { // 如果不等,则 cur 不重复,可以保存 newcur.next = cur; // 别忘了移动 newcur newcur = cur; // 别忘了也要更新 cur cur = cur.next; } } // 还需要断开原始连接 newcur.next = null; return dummy.next; }
题解思路(更加优雅):curr 从 dummy 开始
判断 cur.next.val == cur.next.next.val(注意 cur 是不重复的链表上的最新节点,其包括自己在内的之前的节点都不重复):
如果相等,说明 cur 的下一个节点是重复节点,不能考虑在内。此时保存其值 x(用于在 while 循环中不断找到和该节点重复的节点),并开启一个新的 while 循环,不断跳过 x 重复的节点 cur.next = cur.next.next(一直操作下去直到退出 while 循环时,cur 将指向与 x 重复的节点的下一个节点上)
如果不相等,说明 cur 的下一个节点肯定不重复,进行保存
这样退出循环后,也不需要额外设置 null 了,因为在上面的 while 循环里会将 null 保存进去
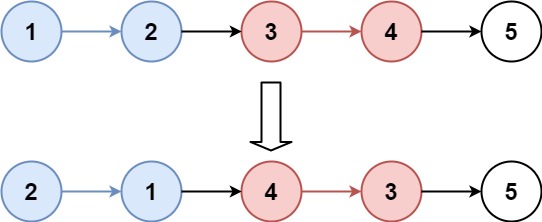
public ListNode reverseKGroup(ListNode head, int k){ if (head == null) { returnnull; } // 先遍历一遍链表确定总长度 N int N = 0; ListNode cur = head; while (cur != null) { N++; cur = cur.next; }
// 分组个数 int group = N / k; if (group < 1) { return head; }
cur = head;
ListNode next = null; ListNode newHead = null;
// 维护一个二维数组,保存每一组的头和尾 ListNode[][] record = new ListNode[group][2]; // 需要记录第一组翻转后的头结点 for (int i = 0; i < group; i++) { // 先保存原本的头(变为新的尾)到数组 record[i][1] = cur; // 翻转链表 for (int j = 0; j < k; j++) { next = cur.next; cur.next = newHead; newHead = cur; // 这一步会不断保存下一个节点,从而在当前组的末尾 tail 时保存了下一个组的头节点 // 从而可以在下一个 for 循环中成功 record[i][1] = cur 记录到新的组的头节点 cur = next; } // 保存翻转后的头节点 cur record[i][0] = newHead;
// 下一组的 head 就是 cur // 准备开始下一组的遍历 }
// 将每一组的连接起来 for (int i = 0; i < group - 1; i++) { // i组的尾指向i+1组的头 record[i][1].next = record[i + 1][0]; } // 最后一组的尾指向cur的下一个 record[group - 1][1].next = cur;