https://blog.csdn.net/u011863024/article/details/115721328
The Elastic Stack,包括 Elasticsearch、 Kibana、 Beats 和 Logstash(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
Elaticsearch,简称为 ES, 是一个开源的高扩展的分布式全文搜索引擎 , 是整个 ElasticStack 技术栈的核心,是一个可以用于检索 、存储 和分析 的引擎。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。
一般传统数据库,全文检索都实现的很鸡肋,因为一般也没人用数据库存文本字段。进行全文检索需要扫描整个表,如果数据量大的话即使对 SQL 的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
基于以上原因可以分析得出,在一些生产环境中,使用常规的搜索方式,性能是非常差的:
搜索的数据对象是大量的非结构化的文本数据
文件记录量达到数十万或数百万个甚至更多。
支持大量基于交互式文本的查询
需求非常灵活的全文搜索查询
对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足
对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。为了解决结构化数据搜索和非结构化数据搜索性能问题,我们就需要专业,健壮,强大的全文搜索引擎
这里说到的全文搜索引擎 指的是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程(倒排索引)。
ELK 是 Elasticsearch、Logstash、 Kibana 三大开源框架首字母大写简称。市面上也被称为 Elastic Stack。
其中 Elasticsearch 是一个基于 Lucene、分布式、通过 Restful 方式进行交互的近实时搜索平台框架 。像百度、谷歌这种大数据全文搜索引擎的场景都可以使用 Elasticsearch 作为底层支持框架,可见 Elasticsearch 提供的搜索能力确实强大,市面上很多时候我们简称 Elasticsearch 为ES。
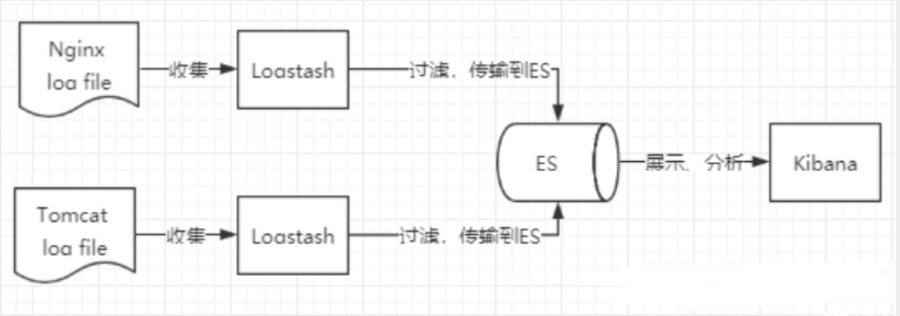
Logstash 是 ELK 的中央数据流引擎 ,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)。
Kibana 可以将 ElasticSearch 的数据通过友好的页面展示出来,提供实时分析的功能。
市面上很多开发只要提到 ELK 能够一致说出它是一个日志分析架构技术栈总称,但实际上 ELK 不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性,并非唯一性。
收集清洗数据(Logstash) ==> 搜索、存储(ElasticSearch) ==> 展示(Kibana)
GitHub:2013 年初,抛弃了 Solr,采取 Elasticsearch 来做 PB 级的搜索。 “GitHub 使用Elasticsearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码”。
维基百科:启动以 Elasticsearch 为基础的核心搜索架构
百度:目前广泛使用 Elasticsearch 作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部 20 多个业务线(包括云分析、网盟、预测、文库、直达号、钱包、 风控等),单集群最大 100 台机器, 200 个 ES 节点,每天导入 30TB+数据。
新浪:使用 Elasticsearch 分析处理 32 亿条实时日志。
阿里:使用 Elasticsearch 构建日志采集和分析体系。
Stack Overflow:解决 Bug 问题的网站,全英文,编程人员交流的网站。
是 apache软件基金会 4 jakarta 项目组的一个子项目
是一个开放源代码的全文检索引擎工具包
不是一个完整的全文检索引擎,而是一个全文检索引擎的架构 ,提供了完整的查询引擎和索引引擎,部分文本分析 当前以及最近几年最受欢迎的免费 Java 信息检索程序库 。
Lucene 和 ElasticSearch 的关系:ElasticSearch 基于 Lucene 做了封装和增强 。ES 使用 Java 开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的 是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
Solr 是 Apache 下的一个顶级开源项目,采用 Java 开发,它是基于Lucene的全文搜索服务器 。Solr 提供了比 Lucene 更为丰富的查询语言 ,同时实现了可配置 、可扩展 ,并对索引、搜索性能进行了优化
Solr 可以独立运行 ,运行在 letty,Tomcat 等这些 Selrvlet 容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据 XML 文档添加、删除、更新 索引。Solr 搜索只需要发送HTTP GET请求,然后对 Solr 返回 XML、JSON 等格式的查询结果进行解析,组织页面布局
Solr 不提供构建 UI 的功能,Solr提供了一个管理界面,通过管理界面可以查询 Solr 的配置和运行情况
Solr 是基于 Lucene 开发企业级搜索服务器,实际上就是封装了lucene.
Solr 是一个独立的企业级搜索应用服务器,它对外提供类似于 Web-service 的 API 接口 。用户可以通过 HTTP 请求,向搜索引擎服务器提交指定格式的文件,生成索引。也可以通过提出查找请求,并得到返回结果
https://www.kuangstudy.com/bbs/1354069127022583809
ElasticSearch 是一个实时分布式搜索和分析引擎 ,它让你以前所未有的速度处理大数据成为可能。
它用于全文搜索、结构化搜索、分析
维基百科使用 ElasticSearch 提供全文搜索 并高亮关键字 ,以及输入实时搜索 (search-asyou-type)和搜索纠错 (did-you-mean)等搜索建议功能。
英国卫报使用 ElasticSearch 结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应。
StackOverflow 结合全文搜索与地理位置查询,以及 more-like-this 功能来找到相关的问题和答案。
Github 使用 ElasticSearch 检索 1300 亿行的代码。
ElasticSearch 是一个基于 Apache Lucene 的开源搜索引擎。无论在开源还是专有领域,Lucene可被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。但是,Lucene 只是一个库 。 想要使用它,你必须使用 Java 来作为开发语言并将其直接集成到你的应用中。更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
ElasticSearch 也使用 Java 开发并使用 Lucene 作为其核心来实现所有引和搜索的功能,但是它的目的 是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
ElasticSearch 与 Solr 比较:
当单纯的对已有数据进行搜索时,Solr 更快
当实时建立索引时,Solr 会产生 io 阻塞,查询性能较差,ElasticSearch 具有明显的优势
随着数据量的增加,Solr 的搜索效率会变得更低,而 ElasticSearch 却没有明显的变化
Solr 利用 Zookeeper 进行分布式管理,而 ElasticSearch 自身带有分布式协调管理功能
Solr 支持更多格式的数据,比如JSON/XML/CSV,而 Elasticsearch 仅支持 JSON 文件格式
Solr 官方提供的功能更多,而Elasticsearch本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要 kibana 友好支撑
Solr 查询快,但更新索引时慢(即插入删除慢) ,用于电商等查询多的应用。ES 建立索引快 (实时性查询快),用于 facebook,新浪等搜索。Solr是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
Solr 比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而Elasticsearch相对开发维护者较少,更新太快,学习使用成本较高。
在 Docker 下快速安装 ElasticSearch 7.4.2:
下载镜像文件
1 2 3 $ docker pull elasticsearch:7.4.2 $ docker pull kibana:7.4.2
配置
1 2 3 4 5 $ mkdir -p /mydata/elasticsearch/config $ mkdir -p /mydata/elasticsearch/data $ mkdir -p /mydata/elasticsearch/plugins $ echo "http.host: 0.0.0.0" >/mydata/elasticsearch/config/elasticsearch.yml $ chmod -R 777 /mydata/elasticsearch/
启动(9300 端口为 Elasticsearch 集群间组件的通信端口, 9200 端口为浏览器访问的 HTTP 请求端口)
1 2 3 4 5 6 7 $ docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \ -e "discovery.type=single-node" \ -e ES_JAVA_OPTS="-Xms64m -Xmx512m" \ -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \ -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ -d elasticsearch:7.4.2
设置开启启动
1 $ docker update elasticsearch --restart=always
启动 Kibana
1 2 $ docker run --name kibana -e ELASTICSEARCH_HOSTS=http://yuyunzhao.cn:9200 -p 5601:5601 -d kibana:7.4.2
在浏览器访问 5601 端口即可进入到界面
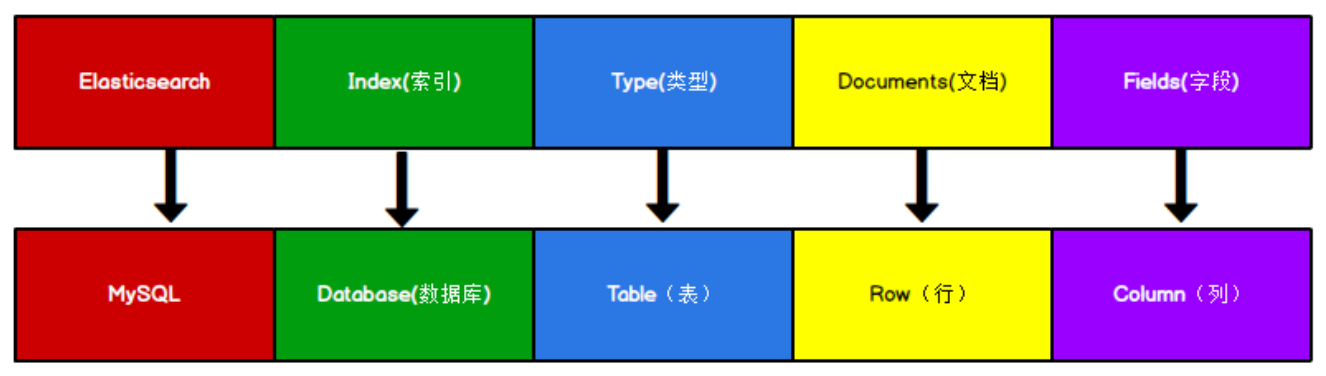
Elasticsearch 是面向文档型数据库 ,一条数据在这里就是一个文档。将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比:
ES 里的 Index 可以看做一个库,而 Types 相当于表, Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化, Elasticsearch 6.X 中,一个 index 下已经只能包含一个type, Elasticsearch 7.X 的一些版本中,Type 的概念已经被删除了。
ElasticSearch 在后台把每个索引划分成多个分片 ,每分分片可以在集群中的不同服务器间迁移。一个人就是一个集群,即启动的 ElasticSearch 服务,默认就是一个集群,且默认集群名为ElasticSearch 。
一个索引类型中,包含多个文档,比如说文档1,文档2。当我们索引一篇文档时,可以通过这样的顺序找到它:索引 => 类型 => 文档ID ,通过这个组合我们就能索引到某个具体的文档。 注意:ID不必是整数,实际上它是个字符串。
文档(“行”)
之前说 ElasticSearch 是面向文档的,那么就意味着索引和搜索数据的最小单位是文档 ,ElasticSearch中,文档有几个重要属性:
自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value
可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的
灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在 ElasticSearch 中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整型。因为 ElasticSearch 会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在 ElasticSearch 中,类型有时候也称为映射类型。
类型(“表”)
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如 name 映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么 ElasticSearch 是怎么做的呢?
ElasticSearch 会自动将新字段加入映射,但是这个字段的不确定它是什么类型,ElasticSearch 就开始猜,如果这个值是18,那么 EasticSearch 会认为它是整型。但是 ElasticSearch 也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用。
索引(“库”)
索引是映射类型的容器, ElasticSearch 中的索引是一个非常大的文档集合。 索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。
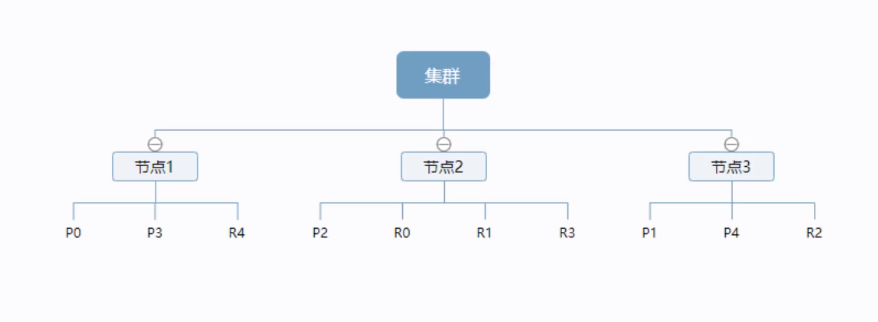
一个集群至少有一个节点,而一个节点就是一个 ElasticSearch 进程,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个 5 个分片(primary shard,又称主分片)构成的,每一个主分片会有一个副本(replica shard,又称复制分片)
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于失。实际上,一个分片是一个Lucene索引(一个ElasticSearch索引包含多个Lucene索引 ) ,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字 。不过,等等,倒排索引是什么鬼?
正排索引(传统):
id
content
1001
my name is zhang san
1002
my name is li si
倒排索引(将一条语句按照关键字进行分词拆分,保存每个关键字的 id):
keyword
id
name
1001, 1002
zhang
1001
更多高级原理见博客:https://blog.csdn.net/u011863024/article/details/115721328
对比关系型数据库,创建索引就等同于创建数据库。四种类型的 RESTful 请求概览:
method
URL
描述
PUT(创建,修改)
localhost:9200/索引名称/类型名称/文档id
创建文档(指定文档id)
POST(创建)
localhost:9200/索引名称/类型名称
创建文档(随机文档id)
POST(修改)
localhost:9200/索引名称/类型名称/文档id
修改文档
POST(修改)
localhost:9200/索引名称/类型名称/文档id/_update
修改文档(会进行数据对比)
DELETE(删除)
localhost:9200/索引名称/类型名称/文档id
删除文档
GET(查询)
localhost:9200/索引名称/类型名称/文档id
通过文档ID查询
GET(查询)
localhost:9200/索引名称/类型名称/_search
条件查询
创建文档有两种方式:
PUT 请求 :幂等性 操作。必须指定文档 id(必须明确知道要操作的对象);如果该文档不存在,就创建该文档;如果文档已经存在,就直接整个替换文档内容 (此时为修改请求)。POST 请求 :非幂等性 操作。可以不指定文档 id(也可以指定);如果不指定 id,则新增数据时服务器自动为该文档创建 一个 id;如果指定 id,则以该 id 创建文档(如果文档已存在,则 POST 修改请求会修改目标对象的部分内容 )
PUT 和 POST 幂等性的讨论 :
PUT:幂等性操作。因为想发出 PUT 请求时必须指定文档 id(必须明确要操作的对象),那么无论发出多少次请求,始终都是在操作该对象,对其内容进行修改,并不会导致创建重复的该对象。
POST:非幂等性操作。因为 POST 请求可以不指定文档 id,这样在发出多次相同的 POST 请求时,如果不指定 id,服务器会创建多个重复的对象(内容相同,但 id 都是服务器随机生成的)
https://cloud.tencent.com/developer/news/39873
总结:使用 PUT 时,必须明确知道要操作的对象,如果对象不存在,创建对象;如果对象存在,则全部替换 目标对象。同样 POST 既可以创建对象,也可以修改对象。但用 POST 创建对象时,之前并不知道要操作的对象,由 HTTP 服务器为新创建的对象生成一个唯一的 URI;使用 POST 修改已存在的对象时,一般只是修改目标对象的部分内容 。
查询数据通常用 GET 请求,同时可以选择是否指定文档 id:
如果指定文档 id,类似于 MySQL 中以指定主键 id 的方式(主键查询)来查询数据,只会查出指定 id 的文档数据。
如果不指定文档 id,则需要在 URL 里添加 _search 字段,表明进行条件查询 (类似于 MySQL 里的 WHERE), 同时需要在请求体里添加条件查询的条件。
示例:http://localhost:9200/custom/external/1
1 2 3 4 5 6 7 8 9 10 11 12 { "_index" : "customer" , "_type" : "external" , "_id" : "1" , "_version" : 1 , "_seq_no" : 0 , "_primary_term" : 1 , "found" : true , "_source" : { "name" : "John Doe" } }
修改文档有两种方式:
PUT 请求 :全量更新 。必须指定所有字段的值,否则漏写的字段将被覆盖为默认值。并且每次修改后,_version 字段的值都会加一。POST 请求 :局部更新 。漏写的字段不会被覆盖。只会更新 POST 请求体里携带的字段,没有指定的字段的值不会被改变。如果 URL 里指定了 _update,则此时的 POST 请求会先进行一次检查,判断原数据的值是否和要更新的值相等:
如果相等,则不执行修改操作,_version 字段的值不会增加
如果不相等,才会执行修改操作,_version 字段的值加一
不论是 PUT 请求还是 POST 请求,只要 URL 里不指定 _update,就不会执行重复校验。只有 POST 请求中指定了 _update,才会进行重复校验
删除文档只能使用 DELETE 请求,并明确指定文档 id。
在请求中添加 _bulk 关键字可以进行批量操作:
1 2 3 4 5 6 7 POST customer/external/_bulk # 两行是一条文档 {"index":{"_id":"1"}} {"name":"John Doe"} # 两行是一条文档 {"index":{"_id":"2"}} {"name":"John Doe"}
语法格式
1 2 3 4 5 6 # 两行是一条文档 {action:{metadata}} {requeestBody} # 两行是一条文档 {action:{metadata}} {requesetbod }
index 是新建索引,会覆盖文档;create 是新建文档,不会覆盖文档
复杂实例:
1 2 3 4 5 6 7 8 POST /_bulk {"delete" :{"_index" :"website" ,"_type" :"blog" ,"_id" :"123" }} {"create" :{"_index" :"website" ,"_type" :"blog" ,"_id" :"123" }} {"title" :"my first blog post" } {"index" :{"_index" :"website" ,"_type" :"blog" }} {"title" :"my second blog post" } {"update" :{"_index" :"website" ,"_type" :"blog" ,"_id" :"123" }} {"doc" :{"title" :"my updated blog post" }}
bulk API 以此按顺序执行所有的action (动作)。如果某个单个的动作因任何原因而失败,它将继续处理它后面剩余的动作。当 bulkAPI 返回时,它将提供每个动作的状态(与发送的顺序相同),可以借此检查一个指定的动作是否失败了。
在请求中添加 _cat 字段,可以用于查看 ES 服务器中的一些信息,例如:
GET /_cat/nodes:查看所有节点GET /_cat/health:查看 es 健康状况GET /_cat/master:查看主节点GET /_cat/incices:查看所有索引 show databases
其他表头:
表头
含义
health
当前服务器健康状态: green(集群完整) yellow(单点正常、集群不完整) red(单点不正常)
status
索引打开、关闭状态
index
索引名
uuid
索引统一编号
pri
主分片数量
rep
副本数量
docs.count
可用文档数量
docs.deleted
文档删除状态(逻辑删除)
store.size
主分片和副分片整体占空间大小
pri.store.size
主分片占空间大小
前面介绍到,在请求的 URL 中添加 _search 字段,表明进行条件查询 (类似于 MySQL 里的 WHERE), 同时需要在请求体里添加条件查询的条件。
常用参数:
query:类似于 where,在其内添加各种匹配规则以实现条件查询_source:过滤字段sort:排序form、size 分页
匹配查询分为以下几种:
match:针对 text 文本类型 的文档
如果字段类型是数字 类型,则会精确匹配 ,只匹配出等于该值的文档
如果字段类型是字符串 类型,则会模糊匹配 ,先使用分词器解析分析文档,然后进行查询。分词器会将该字符串拆分成多个单词,从而匹配出包含这些单词中的任何一个的文档,并再按照评分 score (包含这些单词的比例)对匹配到的文档进行排序
如果某个字段上加了 keyword(例如 name.keyword),就代表该字段查询时不进行分词,要精确匹配
match_all:查询所有,不做条件匹配match_phrase:将需要匹配的值当成一个整体单词(不分词 )进行检索multi_match:同时设置多个条件,需要同时满足这些条件才算匹配term:针对非文本类型 的文档(例如 number/date/keyword),精确匹配 具体数值,不进行分词,接通过倒排索引 指定词条查询。terms:针对对非文本类型 的文档,可以制定多个值,表示精确匹配这些值中的任意一个(或逻辑)
text 和 keyword 的区别:
text:
支持分词 ,全文检索 、支持模糊、精确查询,不支持聚合、排序操作;text 类型的最大支持的字符长度无限制,适合大字段存储;
keyword:
不进行分词 ,直接索引 、支持模糊、支持精确匹配,支持聚合、排序操作。keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above 指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果 。
复合语句可以合并任何其他嵌套语句,包括复合语句,了解这一点是很重要的,这就意味着,复合语句之间可以互相嵌套,可以表达式非常复杂的逻辑
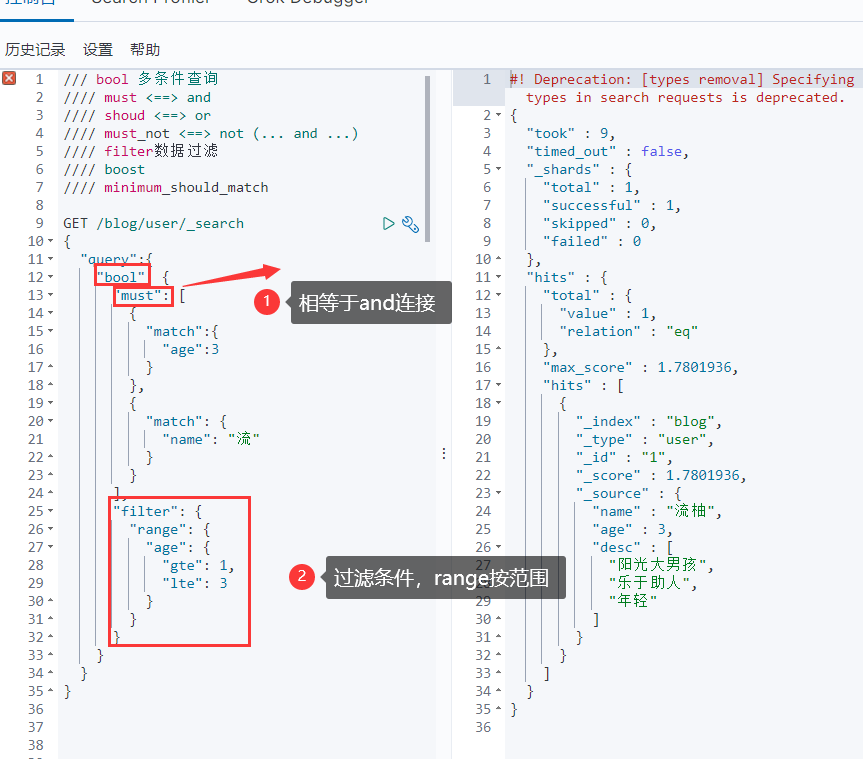
多条件查询 (bool),其都需要写在 query 字段内,都属于条件查询:
must:必须达到 must列举的所有条件should:应该达到 should列举的条件,如果达到会增加相关文档的评分 ,并不会改变查询的结果 ,如果 query 中只有 should 且只有一种匹配规则,那么 should 的条件就会被作为默认匹配条件而去改变查询结果。should 是加分项 ,不满足也能查出来。只是如果满足会加分 must_not:必须不是指定的情况。must_not 不会额外贡献得分 ,但是其是一个 filter,不满足直接不显示filter:条件过滤。效果和 must 类似,也能检索出目标记录,但是不会记录相关性得分,不满足 filter 的直接过滤,满足的留下。且满足的也不会额外增加相关性得分 。filter 因为不涉及计算评分,因此查询效率更高
上图中的相当于 and 不正确
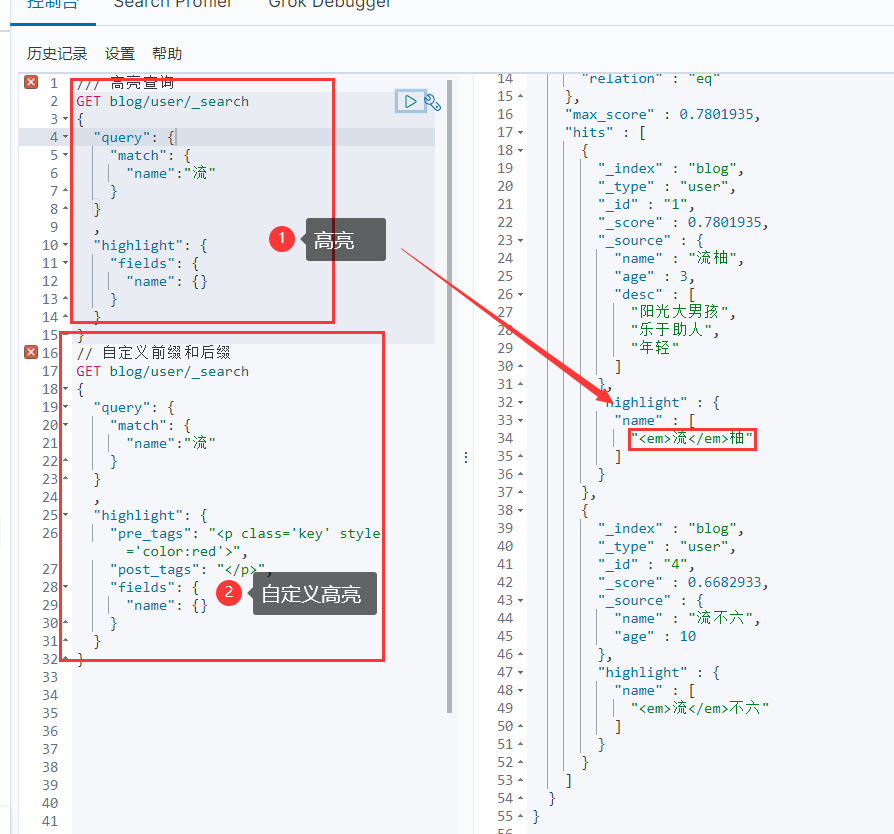
可以添加高亮查询参数,使得匹配到的分词添加一段高亮标签 <em>xxxx</em>:
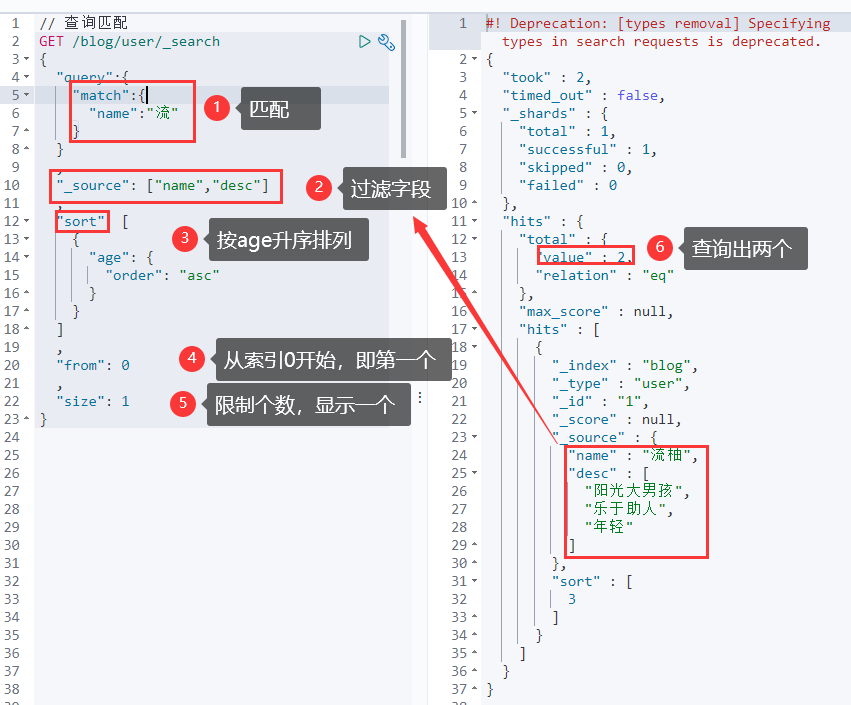
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 GET blog/user/_search { "query" : { "match" : { "name" :"流" } } , "highlight" : { "fields" : { "name" : {} } } }
自定义前缀和后缀:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 GET blog/user/_search { "query" : { "match" : { "name" :"流" } } , "highlight" : { "pre_tags" : "<p class='key' style='color:red'>" , "post_tags" : "</p>" , "fields" : { "name" : {} } } }
聚合查询(aggregations)允许使用者对 ES 文档进行统计分析 ,类似于关系型数据库中的 group by,当然还有很多其他的聚合,例如取最大值 max、平均值 avg 等等。使用格式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 GET bank/_search { "query" : { "match" : { "address" : "mill" } }, "aggs" :{ "price_group" :{ "terms" :{ "field" :"price" } } } }
示例一:搜索 address 中包含 mill 的所有人的年龄分布以及平均年龄
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 GET bank/_search { "query" : { "match" : { "address" : "mill" } }, "aggs" : { "ageAgg" : { "terms" : { "field" : "age" , "size" : 10 } }, "ageAvg" :{ "avg" : { "field" : "age" } }, "balanceAvg" :{ "avg" : { "field" : "balance" } } }, "size" :0 }
示例二:按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 GET bank/_search { "query" :{ "match_all" : {} }, "aggs" : { "ageAgg" : { "terms" : { "field" : "age" , "size" : 10 }, "aggs" : { "ageAvg" : { "avg" : { "field" : "balance" } } } } } }
示例三:查出所有年龄分布,并且这些年龄段中M的平均薪资和 F 的平均薪资以及这个年龄段的总体平均薪资
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 GET /bank/_search { "query" : { "match_all" : {} }, "aggs" : { "ageAgg" : { "terms" : { "field" : "age" , "size" : 100 }, "aggs" : { "genderAgg" : { "terms" : { "field" : "gender.keyword" , "size" : 10 }, "aggs" : { "balanceAvg" : { "avg" : { "field" : "balance" } } } } } } } }
其中:
terms 用于数据统计(统计某个字段的数据分布情况)avg 计算平均值
nested 用于定义嵌入式对象 。
文档的内部对象需要定义为 nested 类型。这是因为,ES 内部的 Lucene 会将普通类型的对象进行扁平化处理。如果 Lucene 对文档进行了扁平化,则各个不同文档间的内部对象数据就会被存储在一起,就不符合实际存储情况了。例如,某个文档拥有一个内部数据 comments,其又有多个字段(name/comment/age等),那么被扁平化后的文档数据:
1 2 3 4 5 6 7 8 9 10 11 { "title" : [ invest, money ], "body" : [ as, investing, money, please, soon, start ], "tags" : [ invest, money ], "published_on" : [ 18 Oct 2017 ] "comments.name" : [ smith, john, william ], "comments.comment" : [ after, article, good, i, investing, nice, post, reading, started, this, very ], "comments.age" : [ 33 , 34 , 38 ], "comments.rating" : [ 7 , 8 , 9 ], "comments.commented_on" : [ 20 Nov 2017 , 25 Nov 2017 , 30 Nov 2017 ] }
显然多个文档的 comments信息被混在一起了,就不符合实际存储情况了。
更多详细介绍见:https://elastic.blog.csdn.net/article/details/82950393
因此,当一个对象中又嵌套包含另一个对象时,需要将该对象类型设置为 nested。这样 ES 内部的 Lucene 就不会将这个对象进行扁平化处理。
使用 nested 的示例:将内部对象 attrs 设置为 nested 类型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 PUT product { "mappings" :{ "properties" : { "attrs" : { "type" : "nested" , "properties" : { "attrId" : {"type" : "long" }, "attrName" : { "type" : "keyword" , "index" : false , "doc_values" : false }, "attrValue" : {"type" : "keyword" } } } } } }
Mapping(映射) 是用来定义一个文档(document)以及他所包含的属性(field)是如何存储索引的,比如使用 mapping 来定义的:
哪些字符串属性应该被看做全文本属性(full text fields)
那些属性包含数字,日期或者地理位置
文档中的所有属性是能被索引(_all 配置)
日期的格式
自定义映射规则来执行动态添加属性
查看某个索引的所有类型信息:
如果在创建索引时不显式指定每个字段的类型,则 ES 会根据字段的值自动推测该字段的类型。
创建索引,指定映射(不设置值):
1 2 3 4 5 6 7 8 9 PUT /my_index { "mappings" : { "properties" : { "age" : {"type" : "integer" }, "email" : {"type" : "keyword" } } } }
如果想在一个已存在的索引上添加新的字段映射:
1 2 3 4 5 6 7 8 9 PUT /my_index/_mapping { "properties" :{ "employeeid" :{ "type" :"keyword" , "index" :false } } }
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 PUT product { "mappings" :{ "properties" :{ "skuId" :{ "type" :"long" }, "spuId" :{ "type" :"keyword" }, "skuTitle" :{ "type" :"text" , "analyzer" : "ik_smart" }, "skuPrice" :{ "type" :"keyword" }, "skuImg" :{ "type" :"text" , "analyzer" : "ik_smart" }, "saleCount" :{ "type" :"long" }, "hasStock" :{ "type" :"boolean" }, "hotScore" :{ "type" :"long" }, "brandId" :{ "type" :"long" }, "catelogId" :{ "type" :"long" }, "brandName" :{ "type" :"keyword" , "index" : false , "doc_values" : false }, "brandImg" :{ "type" :"keyword" , "index" : false , "doc_values" : false }, "catalogName" :{ "type" :"keyword" , "index" : false , "doc_values" : false }, "attrs" :{ "type" :"nested" , "properties" : { "attrId" :{ "type" :"long" }, "attrName" :{ "type" :"keyword" , "index" :false , "doc_values" :false }, "attrValue" : { "type" :"keyword" } } } } } }
其中,一旦为 字段设置了 "doc_values": false,则其就不能用来进行聚合了。如果想要对该字段进行聚合,就不能设置为 false。
如果想将某个索引内的数据迁移到另一个索引内,则可以使用如下方法:
先创建新索引 new_twitter 的正确映射
然后进行迁移:
1 2 3 4 5 6 7 8 9 POST _reindex // [固定写法] { "source" :{ "index" :"twitter" }, "dest" :{ "index" :"new_twitter" } }
如果想将旧索引的 type下的数据进行迁移,则方法为:
1 2 3 4 5 6 7 8 9 10 POST _reindex { "source" : { "index" :"twitter" , "type" :"tweet" }, "dest" :{ "index" :"twweets" } }
更多细节参考:
Java 中的 ES 客户端有多种选择,具体见官方文档: https://www.elastic.co/guide/en/elasticsearch/client/index.html
本章将介绍 Java REST Client 的配置和使用。与 Spring Data 的整合配置与使用见博客:https://blog.csdn.net/u011863024/article/details/115721328
导入依赖:
1 2 3 4 5 6 <dependency > <groupId > org.elasticsearch.client</groupId > <artifactId > elasticsearch-rest-high-level-client</artifactId > <version > 7.4.2</version > </dependency >
配置类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @NoArgsConstructor @Data @Configuration public class MallElasticSearchConfig public static final RequestOptions COMMON_OPTIONS; static { RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder(); COMMON_OPTIONS = builder.build(); } @Bean public RestHighLevelClient esRestClient () RestClientBuilder builder = RestClient.builder( new HttpHost("localhost" , 9200 , "http" )); RestHighLevelClient client = new RestHighLevelClient(builder); return client; } }
注入 RestHighLevelClient:
1 2 @Autowired public RestHighLevelClient restHighLevelClient;
创建索引
1 2 3 4 5 6 7 8 9 @Test public void testCreateIndex () throws IOException CreateIndexRequest request = new CreateIndexRequest("liuyou_index" ); CreateIndexResponse response = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT); System.out.println(response.isAcknowledged()); System.out.println(response); restHighLevelClient.close(); }
获取索引:
1 2 3 4 5 6 7 8 @Test public void testIndexIsExists () throws IOException GetIndexRequest request = new GetIndexRequest("index" ); boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT); System.out.println(exists); restHighLevelClient.close(); }
删除索引:
1 2 3 4 5 6 7 8 @Test public void testDeleteIndex () throws IOException DeleteIndexRequest request = new DeleteIndexRequest("liuyou_index" ); AcknowledgedResponse response = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT); System.out.println(response.isAcknowledged()); restHighLevelClient.close(); }
添加文档:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Test public void testAddDocument () throws IOException User liuyou = new User("liuyou" , 18 ); IndexRequest request = new IndexRequest("liuyou_index" ); request.id("1" ); request.timeout(TimeValue.timeValueMillis(1000 )); request.source(JSON.toJSONString(liuyou), XContentType.JSON); IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT); System.out.println(response.status()); System.out.println(response); }
获取文档信息:
1 2 3 4 5 6 7 8 9 @Test public void testGetDocument () throws IOException GetRequest request = new GetRequest("liuyou_index" ,"1" ); GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT); System.out.println(response.getSourceAsString()); System.out.println(request); restHighLevelClient.close(); }
获取文档并判断其是否存在:
1 2 3 4 5 6 7 8 9 10 @Test public void testDocumentIsExists () throws IOException GetRequest request = new GetRequest("liuyou_index" , "1" ); request.fetchSourceContext(new FetchSourceContext(false )); request.storedFields("_none_" ); boolean exists = restHighLevelClient.exists(request, RequestOptions.DEFAULT); System.out.println(exists); }
更新文档:
1 2 3 4 5 6 7 8 9 10 @Test public void testUpdateDocument () throws IOException UpdateRequest request = new UpdateRequest("liuyou_index" , "1" ); User user = new User("lmk" ,11 ); request.doc(JSON.toJSONString(user),XContentType.JSON); UpdateResponse response = restHighLevelClient.update(request, RequestOptions.DEFAULT); System.out.println(response.status()); restHighLevelClient.close(); }
删除文档:
1 2 3 4 5 6 7 8 @Test public void testDeleteDocument () throws IOException DeleteRequest request = new DeleteRequest("liuyou_index" , "1" ); request.timeout("1s" ); DeleteResponse response = restHighLevelClient.delete(request, RequestOptions.DEFAULT); System.out.println(response.status()); }
查询文档:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 @Test public void testSearch () throws IOException SearchRequest searchRequest = new SearchRequest(); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name" , "liuyou" ); searchSourceBuilder.highlighter(new HighlightBuilder()); searchSourceBuilder.timeout(new TimeValue(60 , TimeUnit.SECONDS)); searchSourceBuilder.query(termQueryBuilder); searchRequest.source(searchSourceBuilder); SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); SearchHits hits = search.getHits(); System.out.println(JSON.toJSONString(hits)); System.out.println("=======================" ); for (SearchHit documentFields : hits.getHits()) { System.out.println(documentFields.getSourceAsMap()); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 @Test public void searchData () throws IOException SearchRequest searchRequest = new SearchRequest(); searchRequest.indices("bank" ); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder.query(QueryBuilders.matchQuery("address" , "mill" )); TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg" ).field("age" ).size(10 ); sourceBuilder.aggregation(ageAgg); AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg" ).field("balance" ); sourceBuilder.aggregation(balanceAvg); searchRequest.source(sourceBuilder); System.out.println("检索条件:" + sourceBuilder.toString()); SearchResponse searchResponse = client.search(searchRequest, MallElasticSearchConfig.COMMON_OPTIONS); System.out.println(searchResponse.toString()); SearchHits hits = searchResponse.getHits(); SearchHit[] searchHits = hits.getHits(); for (SearchHit hit : searchHits) { String sourceAsString = hit.getSourceAsString(); Account accout = JSON.parseObject(sourceAsString, Account.class); System.out.println("account:" + accout ); } Aggregations aggregations = searchResponse.getAggregations(); Terms ageAgg1 = aggregations.get("ageAgg" ); for (Terms.Bucket bucket : ageAgg1.getBuckets()) { String keyAsString = bucket.getKeyAsString(); System.out.println("年龄:" + keyAsString); long docCount = bucket.getDocCount(); System.out.println("个数:" + docCount); } Avg balanceAvg1 = aggregations.get("balanceAvg" ); System.out.println("平均薪资:" + balanceAvg1.getValue()); System.out.println(searchResponse.toString()); }
批量保存文档:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Test public void testBulk () throws IOException BulkRequest bulkRequest = new BulkRequest(); bulkRequest.timeout("10s" ); ArrayList<User> users = new ArrayList<>(); users.add(new User("liuyou-1" ,1 )); users.add(new User("liuyou-2" ,2 )); users.add(new User("liuyou-3" ,3 )); users.add(new User("liuyou-4" ,4 )); users.add(new User("liuyou-5" ,5 )); users.add(new User("liuyou-6" ,6 )); for (int i = 0 ; i < users.size(); i++) { bulkRequest.add( new IndexRequest("bulk" ) .id("" +(i + 1 )) .source(JSON.toJSONString(users.get(i)),XContentType.JSON) ); } BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); System.out.println(bulk.status()); }
真实案例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Test public void testBulk () throws IOException BulkRequest bulkRequest = new BulkRequest(); for (SkuEsModel skuEsModel : skuEsModelList) { IndexRequest indexRequest = new IndexRequest(EsConstant.PRODUCT_INDEX); indexRequest.id(skuEsModel.getSkuId().toString()); String jsonString = JSON.toJSONString(skuEsModel); indexRequest.source(jsonString, XContentType.JSON); bulkRequest.add(indexRequest); } BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, MallElasticSearchConfig.COMMON_OPTIONS); }
https://blog.csdn.net/u011863024/article/details/115721328
一个 tokenizer(分词器)接收一个字符流,将之分割为独立的 tokens (词元,通常是独立的单词),然后输出 token 流。例如,witespace tokenizer 遇到的空白字符时分割文本,它会将文本 “Quick brown fox” 分割为 【Quick brown fox】。
该分词器还负责记录各个 term(词条)的顺序或 position 位置(用于 phrase 短语和 word proximity 词近邻查询),以及 term(词条)所代表的原始 word 的 start 和end 的 character offsets (字符偏移量),用于高亮显示搜索的内容。
Elasticsearch 提供了很多内置的分词器,也可以按照其他开源的分词器(例如 ik 分词器)。例如标准分词器:
1 2 3 4 5 GET http://localhost:9200/_analyze { "analyzer" : "standard" , "text" : "Text to analyze" }
结果中每个元素代表一个单独的词条:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 { "tokens" : [ { "token" : "text" , "start_offset" : 0 , "end_offset" : 4 , "type" : "<ALPHANUM>" , "position" : 1 }, { "token" : "to" , "start_offset" : 5 , "end_offset" : 7 , "type" : "<ALPHANUM>" , "position" : 2 }, { "token" : "analyze" , "start_offset" : 8 , "end_offset" : 15 , "type" : "<ALPHANUM>" , "position" : 3 } ] }
token 是实际存储到索引中的词条start_offset 和 end_offset 指明字符在原始字符串中的位置position 指明词条在原始文本中出现的位置
ik 分词器是一款优秀的汉语分词器。安装方法:从 https://github.com/medcl/elasticsearch-analysis-ik/releases /mydata/elasticsearch/plugins 下即可。
修改 /mydata/elasticsearch/plugins/ik/config 目录下的 IKAnalyzer.cfg.xml 文件,在其内写上远程字典地址:
1 2 3 4 5 6 7 8 9 10 11 12 13 <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd" > <properties > <comment > IK Analyzer 扩展配置</comment > <entry key ="ext_dict" > </entry > <entry key ="ext_stopwords" > </entry > <entry key ="remote_ext_dict" > http://yuyunzhao.cn/es/fenci.txt</entry > </properties >
其中,远程字典文件 /es/fenci.txt 创建在了 nginx 的 /mydata/nginx/html 目录下,这样才可以被其他服务器访问到。
在词典中添加自定义的分词:
添加了分词后记得重新启动 elasticsearch 服务:
1 docker restart elasticsearch
这样在检索时就可以指定分词器为 ik 分词器:
1 2 3 4 5 POST _analyze { "analyzer" : "ik_max_word" , "text" : ["乔碧萝殿下" ] }
本章将介绍云商城项目
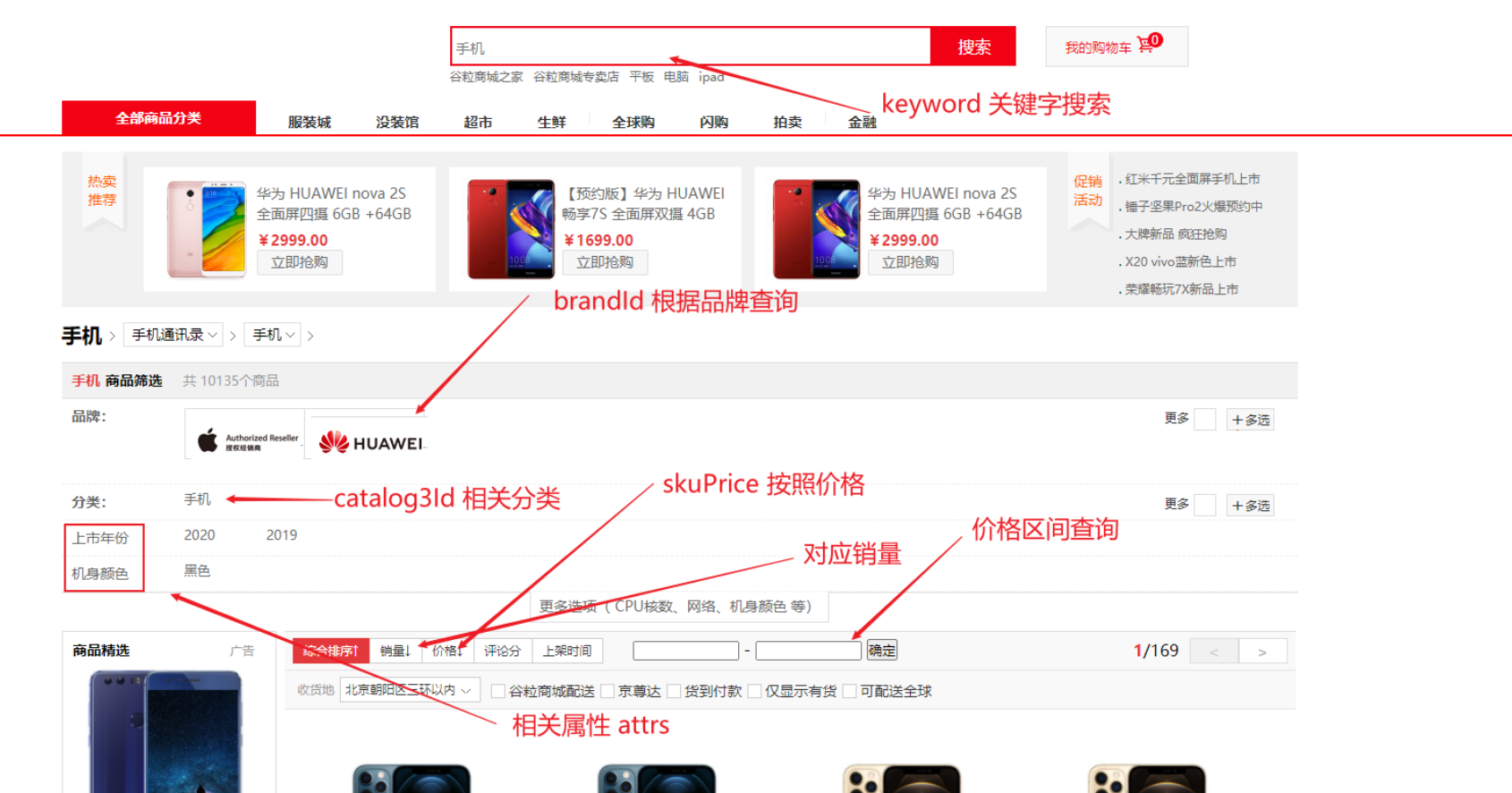
检索服务负责根据前端传来的关键词等参数对商品进行检索。首先介绍前端页面中用户可以用来进行检索的条件:
我们需要根据这些条件构造出搜索条件实体类 SearchParam,该对象中的每个属性都对应了前端传来的查询参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 @Data public class SearchParam private String keyword; private Long catalog3Id; private String sort; private Integer hasStock = 0 ; private String skuPrice; private List<Long> brandId; private List<String> attrs; private Integer pageNum = 1 ; }
同时我们还需要为检索结果设计一个 VO 类 SearchResult ,该类负责保存检索到的所有商品信息 SkuEsModel(具体定义见商品上架 ),并且保存查询结果所涉及到的品牌、商品分类以及商品属性等信息。这些信息将返回给前端进行展示,这样前端就可以根据用户的检索条件显示出符合该条件的所有产品以及其所涉及到的品牌、商品分类以及商品属性等信息。
查询结果实体类 SearchResult:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 @Data public class SearchResult private List<SkuEsModel> products; private Integer pageNum; private Long total; private Integer totalPages; private List<BrandVo> brands; private List<CatalogVo> catalogs; private List<AttrVo> attrs; private List<Integer> pageNavs; @Data public static class BrandVo private Long brandId; private String brandName; private String brandImg; } @Data public static class CatalogVo private Long catalogId; private String CatalogName; } @Data public static class AttrVo private Long attrId; private String attrName; private List<String> attrValue; } }
构建出 DSL 语句,要包含以下几个部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 GET product/_search { "query" : { "bool" : { "must" : [...], "filter" : [...] } }, "sort" : [...], "from" : 0 , "size" : 1 , "hightlight": {...}, // 高亮显示查询的keyword "aggs": {} // 聚合查询 }
DSL 语句示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 GET product/_search { "query" : { "bool" : { "must" : [ { "match" : { "skuTitle" : "华为" } } ], "filter" : [ { "term" : { "catalogId" : "225" } }, { "terms" : { "brandId" : [ "1" , "5" , "9" ] } }, { "nested" : { "path" : "attrs" , "query" : { "bool" : { "must" : [ { "term" : { "attrs.attrId" : { "value" : "8" } } }, { "terms" : { "attrs.attrValue" : [ "2019" ] } } ] } } } }, { "term" : { "hasStock" : { "value" : "false" } } }, { "range" : { "skuPrice" : { "gte" : 0 , "lte" : 7000 } } } ] } }, "sort" : [ { "skuPrice" : { "order" : "desc" } } ], "from" : 0 , "size" :4 , "highlight" : { "fields" : {"skuTitle" : {}}, "pre_tags" : "<b style=color:red>" , "post_tags" : "</b>" }, "aggs" : { "brand_agg" : { "terms" : { "field" : "brandId" , "size" : 10 }, "aggs" : { "brand_name_agg" : { "terms" : { "field" : "brandName" , "size" : 10 } }, "brand_img_agg" : { "terms" : { "field" : "brandImg" , "size" : 10 } } } }, "catalog_agg" : { "terms" : { "field" : "catalogId" , "size" : 10 }, "aggs" : { "catalog_name_agg" : { "terms" : { "field" : "catalogName" , "size" : 10 } } } }, "attr_agg" :{ "nested" : { "path" : "attrs" }, "aggs" : { "attr_id_agg" : { "terms" : { "field" : "attrs.attrId" , "size" : 10 }, "aggs" : { "attr_name_agg" : { "terms" : { "field" : "attrs.attrName" , "size" : 10 } }, "attr_value_agg" :{ "terms" : { "field" : "attrs.attrValue" , "size" : 10 } } } } } } } }
整体逻辑:
前端发送用户选择的检索条件
Spring MVC 将前端发来的请求中的查询参数自动封装到 SearchParam 对象中
Service 层负责根据 SearchParam 去 ES 中检索出符合的商品数据 SkuEsModel,并将其涉及到的品牌、商品分类以及商品属性等信息封装到 SearchResult 中
Spring MVC 将 SearchResult 放到请求域中转发给检索页 search.html,其进行数据渲染
Controller 层代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 @GetMapping(value = {"/search.html","/"}) public String getSearchPage (SearchParam searchParam, Model model, HttpServletRequest request) searchParam.set_queryString(request.getQueryString()); SearchResult result = mallSearchService.getSearchResult(searchParam); model.addAttribute("result" , result); return "search" ; }
Service 层代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 @Slf4j @Service public class MallSearchSeviceImpl implements MallSearchService @Autowired private RestHighLevelClient restHighLevelClient; @Override public SearchResult getSearchResult (SearchParam searchParam) SearchResult searchResult = null ; SearchRequest request = buildSearchRequest(searchParam); try { SearchResponse searchResponse = restHighLevelClient.search(request, MallElasticSearchConfig.COMMON_OPTIONS); searchResult = buildSearchResult(searchParam, searchResponse); } catch (IOException e) { e.printStackTrace(); } return searchResult; } private SearchResult buildSearchResult (SearchParam searchParam, SearchResponse searchResponse) SearchResult result = new SearchResult(); SearchHits hits = searchResponse.getHits(); if (hits.getHits() != null && hits.getHits().length > 0 ) { List<SkuEsModel> skuEsModels = new ArrayList<>(); for (SearchHit hit : hits) { String sourceAsString = hit.getSourceAsString(); SkuEsModel skuEsModel = JSON.parseObject(sourceAsString, SkuEsModel.class); if (!StringUtils.isEmpty(searchParam.getKeyword())) { HighlightField skuTitle = hit.getHighlightFields().get("skuTitle" ); String highLight = skuTitle.getFragments()[0 ].string(); skuEsModel.setSkuTitle(highLight); } skuEsModels.add(skuEsModel); } result.setProduct(skuEsModels); } result.setPageNum(searchParam.getPageNum()); long total = hits.getTotalHits().value; result.setTotal(total); Integer totalPages = (int ) total % EsConstant.PRODUCT_PAGESIZE == 0 ? (int ) total / EsConstant.PRODUCT_PAGESIZE : (int ) total / EsConstant.PRODUCT_PAGESIZE + 1 ; result.setTotalPages(totalPages); List<Integer> pageNavs = new ArrayList<>(); for (int i = 1 ; i <= totalPages; i++) { pageNavs.add(i); } result.setPageNavs(pageNavs); List<SearchResult.BrandVo> brandVos = new ArrayList<>(); Aggregations aggregations = searchResponse.getAggregations(); ParsedLongTerms brandAgg = aggregations.get("brandAgg" ); for (Terms.Bucket bucket : brandAgg.getBuckets()) { Long brandId = bucket.getKeyAsNumber().longValue(); Aggregations subBrandAggs = bucket.getAggregations(); ParsedStringTerms brandImgAgg = subBrandAggs.get("brandImgAgg" ); String brandImg = brandImgAgg.getBuckets().get(0 ).getKeyAsString(); Terms brandNameAgg = subBrandAggs.get("brandNameAgg" ); String brandName = brandNameAgg.getBuckets().get(0 ).getKeyAsString(); SearchResult.BrandVo brandVo = new SearchResult.BrandVo(brandId, brandName, brandImg); brandVos.add(brandVo); } result.setBrands(brandVos); List<SearchResult.CatalogVo> catalogVos = new ArrayList<>(); ParsedLongTerms catalogAgg = aggregations.get("catalogAgg" ); for (Terms.Bucket bucket : catalogAgg.getBuckets()) { Long catalogId = bucket.getKeyAsNumber().longValue(); Aggregations subcatalogAggs = bucket.getAggregations(); ParsedStringTerms catalogNameAgg = subcatalogAggs.get("catalogNameAgg" ); String catalogName = catalogNameAgg.getBuckets().get(0 ).getKeyAsString(); SearchResult.CatalogVo catalogVo = new SearchResult.CatalogVo(catalogId, catalogName); catalogVos.add(catalogVo); } result.setCatalogs(catalogVos); List<SearchResult.AttrVo> attrVos = new ArrayList<>(); ParsedNested parsedNested = aggregations.get("attrs" ); ParsedLongTerms attrIdAgg = parsedNested.getAggregations().get("attrIdAgg" ); for (Terms.Bucket bucket : attrIdAgg.getBuckets()) { Long attrId = bucket.getKeyAsNumber().longValue(); Aggregations subAttrAgg = bucket.getAggregations(); ParsedStringTerms attrNameAgg = subAttrAgg.get("attrNameAgg" ); String attrName = attrNameAgg.getBuckets().get(0 ).getKeyAsString(); ParsedStringTerms attrValueAgg = subAttrAgg.get("attrValueAgg" ); List<String> attrValues = new ArrayList<>(); for (Terms.Bucket attrValueAggBucket : attrValueAgg.getBuckets()) { String attrValue = attrValueAggBucket.getKeyAsString(); attrValues.add(attrValue); List<SearchResult.NavVo> navVos = new ArrayList<>(); } SearchResult.AttrVo attrVo = new SearchResult.AttrVo(attrId, attrName, attrValues); attrVos.add(attrVo); } result.setAttrs(attrVos); List<String> attrs = searchParam.getAttrs(); if (attrs != null && attrs.size() > 0 ) { List<SearchResult.NavVo> navVos = attrs.stream().map(attr -> { String[] split = attr.split("_" ); SearchResult.NavVo navVo = new SearchResult.NavVo(); navVo.setNavValue(split[1 ]); try { R r = productFeignService.info(Long.parseLong(split[0 ])); if (r.getCode() == 0 ) { AttrResponseVo attrResponseVo = JSON.parseObject(JSON.toJSONString(r.get("attr" )), new TypeReference<AttrResponseVo>() { }); navVo.setNavName(attrResponseVo.getAttrName()); } } catch (Exception e) { log.error("远程调用商品服务查询属性失败" , e); } String queryString = searchParam.get_queryString(); String replace = queryString.replace("&attrs=" + attr, "" ).replace("attrs=" + attr+"&" , "" ).replace("attrs=" + attr, "" ); navVo.setLink("http://search.gulimall.com/search.html" + (replace.isEmpty()?"" :"?" +replace)); return navVo; }).collect(Collectors.toList()); result.setNavs(navVos); } return result; } private SearchRequest buildSearchRequest (SearchParam searchParam) SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder(); if (!StringUtils.isEmpty(searchParam.getKeyword())) { boolQueryBuilder.must(QueryBuilders.matchQuery("skuTitle" , searchParam.getKeyword())); } if (searchParam.getCatalog3Id() != null ) { boolQueryBuilder.filter(QueryBuilders.termQuery("catalogId" , searchParam.getCatalog3Id())); } if (searchParam.getBrandId() != null && searchParam.getBrandId().size() > 0 ) { boolQueryBuilder.filter(QueryBuilders.termsQuery("brandId" , searchParam.getBrandId())); } if (searchParam.getHasStock() != null ) { boolQueryBuilder.filter(QueryBuilders.termQuery("hasStock" , searchParam.getHasStock() == 1 )); } RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("skuPrice" ); if (!StringUtils.isEmpty(searchParam.getSkuPrice())) { String[] prices = searchParam.getSkuPrice().split("_" ); if (prices.length == 1 ) { if (searchParam.getSkuPrice().startsWith("_" )) { rangeQueryBuilder.lte(Integer.parseInt(prices[0 ])); } else { rangeQueryBuilder.gte(Integer.parseInt(prices[0 ])); } } else if (prices.length == 2 ) { if (!prices[0 ].isEmpty()) { rangeQueryBuilder.gte(Integer.parseInt(prices[0 ])); } rangeQueryBuilder.lte(Integer.parseInt(prices[1 ])); } boolQueryBuilder.filter(rangeQueryBuilder); } List<String> attrs = searchParam.getAttrs(); BoolQueryBuilder queryBuilder = new BoolQueryBuilder(); if (attrs != null && attrs.size() > 0 ) { attrs.forEach(attr -> { String[] attrSplit = attr.split("_" ); queryBuilder.must(QueryBuilders.termQuery("attrs.attrId" , attrSplit[0 ])); String[] attrValues = attrSplit[1 ].split(":" ); queryBuilder.must(QueryBuilders.termsQuery("attrs.attrValue" , attrValues)); }); } NestedQueryBuilder nestedQueryBuilder = QueryBuilders.nestedQuery("attrs" , queryBuilder, ScoreMode.None); boolQueryBuilder.filter(nestedQueryBuilder); searchSourceBuilder.query(boolQueryBuilder); if (!StringUtils.isEmpty(searchParam.getSort())) { String[] sortSplit = searchParam.getSort().split("_" ); searchSourceBuilder.sort(sortSplit[0 ], sortSplit[1 ].equalsIgnoreCase("asc" ) ? SortOrder.ASC : SortOrder.DESC); } searchSourceBuilder.from((searchParam.getPageNum() - 1 ) * EsConstant.PRODUCT_PAGESIZE); searchSourceBuilder.size(EsConstant.PRODUCT_PAGESIZE); if (!StringUtils.isEmpty(searchParam.getKeyword())) { HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.field("skuTitle" ); highlightBuilder.preTags("<b style='color:red'>" ); highlightBuilder.postTags("</b>" ); searchSourceBuilder.highlighter(highlightBuilder); } TermsAggregationBuilder brandAgg = AggregationBuilders.terms("brandAgg" ).field("brandId" ); TermsAggregationBuilder brandNameAgg = AggregationBuilders.terms("brandNameAgg" ).field("brandName" ); TermsAggregationBuilder brandImgAgg = AggregationBuilders.terms("brandImgAgg" ).field("brandImg" ); brandAgg.subAggregation(brandNameAgg); brandAgg.subAggregation(brandImgAgg); searchSourceBuilder.aggregation(brandAgg); TermsAggregationBuilder catalogAgg = AggregationBuilders.terms("catalogAgg" ).field("catalogId" ); TermsAggregationBuilder catalogNameAgg = AggregationBuilders.terms("catalogNameAgg" ).field("catalogName" ); catalogAgg.subAggregation(catalogNameAgg); searchSourceBuilder.aggregation(catalogAgg); NestedAggregationBuilder nestedAggregationBuilder = new NestedAggregationBuilder("attrs" , "attrs" ); TermsAggregationBuilder attrIdAgg = AggregationBuilders.terms("attrIdAgg" ).field("attrs.attrId" ); TermsAggregationBuilder attrNameAgg = AggregationBuilders.terms("attrNameAgg" ).field("attrs.attrName" ); TermsAggregationBuilder attrValueAgg = AggregationBuilders.terms("attrValueAgg" ).field("attrs.attrValue" ); attrIdAgg.subAggregation(attrNameAgg); attrIdAgg.subAggregation(attrValueAgg); nestedAggregationBuilder.subAggregation(attrIdAgg); searchSourceBuilder.aggregation(nestedAggregationBuilder); log.debug("构建的DSL语句 {}" , searchSourceBuilder.toString()); SearchRequest request = new SearchRequest(new String[]{EsConstant.PRODUCT_INDEX}, searchSourceBuilder); return request; } }