Session 和 Cookie
每个客户端(浏览器)在与服务器端产生连接后,都会在服务器端为该客户端创建一个独有的 Session 对象。Session 就是 Tomcat 服务器内存中保存的一个 Map 对象,所有 Session 对象都放到一个 SessionManager 里进行管理,不同的 Session 代表与不同的客户端进行的会话。
Session 和 Cookie 的关系:
- 在某个客户端(浏览器)第一次访问服务器时,将创建一个 Session 对象,并保存到服务器端
- 同时令客户端保存一个
jsessionid = sessionId的 Cookie。其 key 值是固定的jsessionid,value 是sessionId。浏览器关闭前该 Cookie 将一直存在 - Cookie 中还保存着一个重要信息:
Domain(域名)。该值保存着该 Cookie 可以访问的网站域名。当访问一个网站时,浏览器会从目前存活的所有 Cookie 中选出Domain匹配当前网站的那些 Cookie,并在访问该网站时在请求头里带上这些 Cookie。 - 之后 Cookie 存在期间每次访问对应
Domain的服务器都将带上 Cookie 信息(在请求头中) - 浏览器关闭后,清除掉 Cookie,服务器端清除掉 Session
Cookie 是浏览器负责保存,Session 是服务器负责保存。Cookie 中保存着 Session 信息,对应唯一的一个 Session。
示意图:

关于 Session 和 Cookie 的完整介绍见文章【JavaWeb】Session 和 Cookie
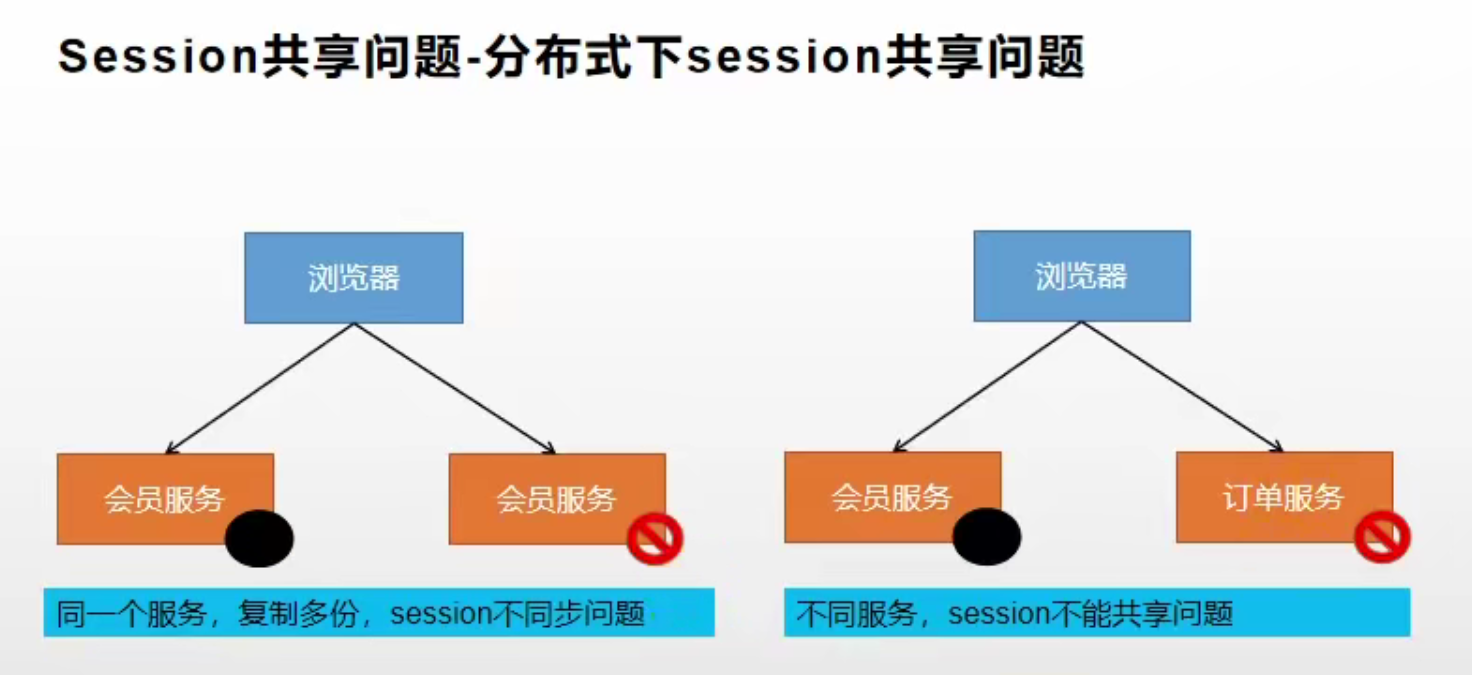
Session 共享问题
在分布式下存在着 Session 共享问题:
- 不同微服务间无法共享 Session:因为每个 Session 都是存储在当前微服务的内存中的,所以无法获取其他微服务内存中的 Session 里数据,即:Session 不能跨不同的域名共享
- 在集群环境下同一个服务的不同实例也无法共享:在负载均衡算法作用下,可能第一次访问节点1,将数据存储到了节点1的 Session 里。而第二次访问节点2时,其内并没有保存节点1里的 Session 数据,所以仍然无法共享
二者的共同原因是:Session 是保存在服务器的内存中的,A 服务内存中的 Session 数据显然无法被 B 服务访问到:
转发不需要考虑 Session 共享问题。因为转发是可以直接在请求域中传递数据的,根本不需要保存到 Session。只有重定向才需要从 Session 中取数据
Session 共享问题解决方案
方案一:Session 复制(同步)

缺点是每个服务都需要保存其他所有服务的 Session 数据,消耗了大量空间。并且 Session 同步占用了大量的网络宽带,降低了服务器集群的业务处理能力。不推荐使用。
方案二:客户端存储

这种方式的缺点也很明显,同样不推荐使用。
方案三:一致性 Hash
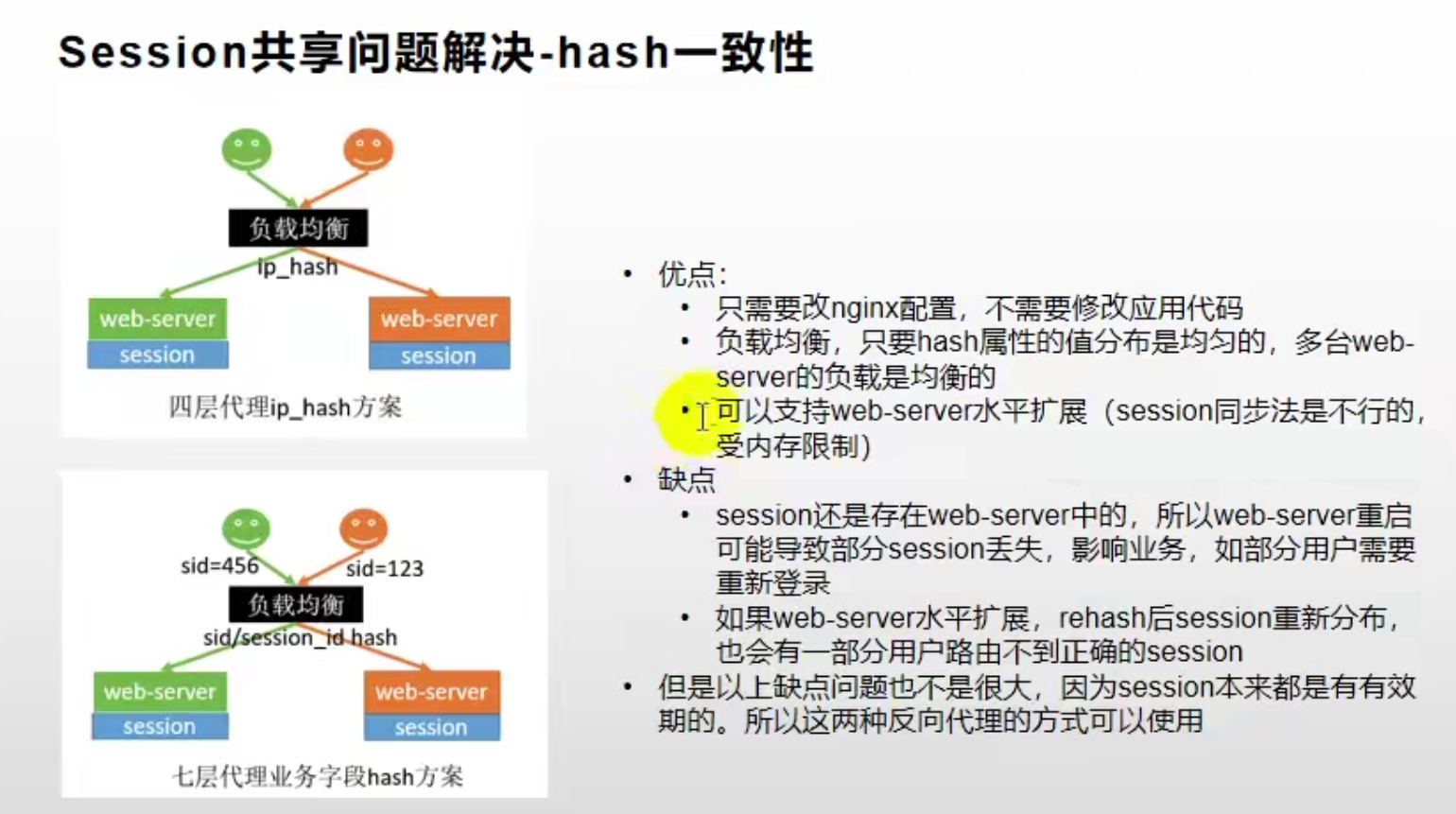
在负载均衡时,使用 ip_hash 策略将同一个 ip 的请求负载均衡到同一个服务节点上,这样就能保证同一个 ip 每次都能访问到同一台服务器上的 Session 了。这种方案的缺点不是很大,可以考虑使用。
方案四:统一存储到 Redis(推荐)
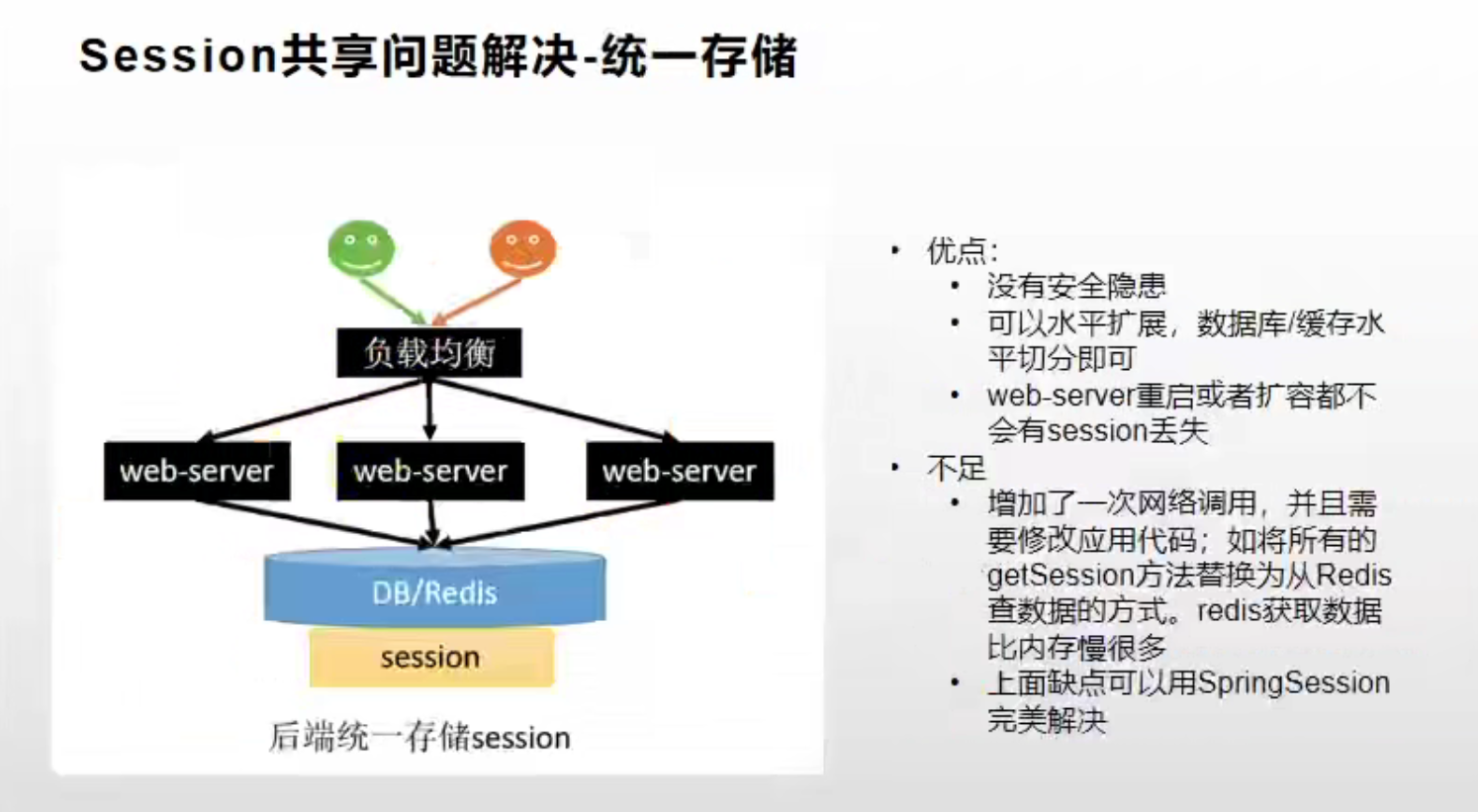
为了做到多个微服务间共享 Session,我们可以把所有微服务的 Session 都统一存储到 Redis 中。这样就可以同时解决两种共享问题,既能让同一服务的不同实例访问到彼此的 Session,也能让不同的微服务也能访问到彼此的 Session。
该方案的缺点就是增加了一次网络调用,并且需要修改代码,例如将原本获取 Session 的方法 getSession() 修改成从 Redis 中读取。不过这些缺点可以使用 Spring Session 完美解决。
方案五:不同服务的子域 Session 共享(推荐)
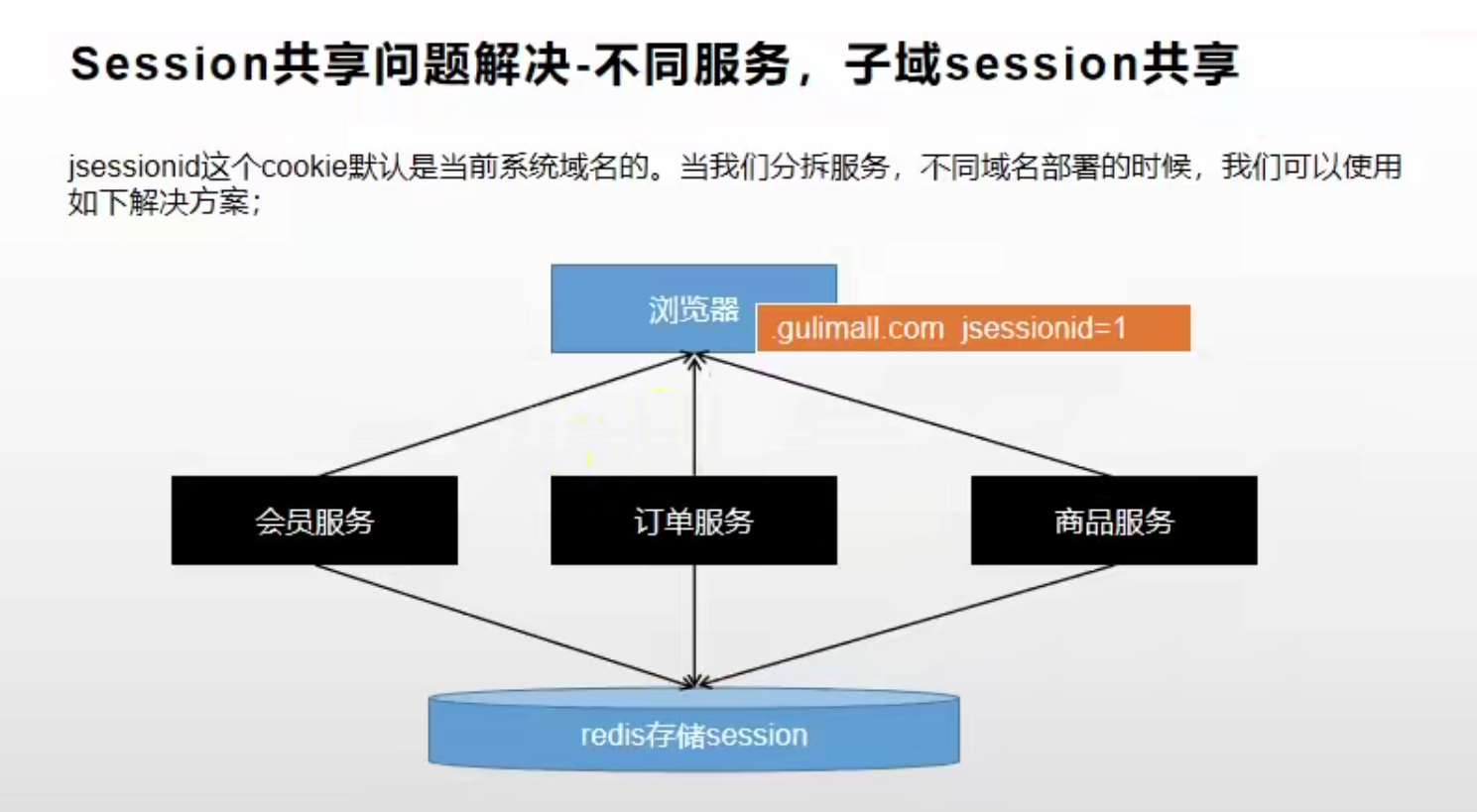
通过方案四,我们实现了所有微服务都可以通过 sessionId 从 Redis 中查询某个 Session 数据。但是问题又来了,其他微服务如何得知要查询的 sessionId 是多少呢? 此时就需要先解释一下浏览器是如何让后端服务知道是要访问哪个 sessionId 的:
Domain:每个 Cookie 都有一个 Domain(域名)。该值保存着该 Cookie 可以访问的网站域名。当访问一个网站时,浏览器会从目前存活的所有 Cookie 中选出 Domain 匹配当前网站的那些 Cookie,并在访问该网站时在请求头里带上这些 Cookie。这些 Cookie 里就保存了 jsessionId = sessionid 信息,也就是其要向该 sessionId 对应的 Session 获取数据。这样,浏览器在发出请求时,就会在请求头里携带上该 Cookie,从而携带了要查询的 sessionId,这样后端服务就可以根据该 Id 去 Redis 中查询出对应的 Session 数据了。
那么我们只需要保证所有微服务都拥有同一份 Cookie 即可。在某个服务给浏览器发放 Cookie 时,需要指定 Domain 为当前服务域名的父域的值,这样浏览器在访问该父域的其他子域时也能带上该 Cookie,也就可以获取到当前服务的 Session 数据(Session 存储在 Redis 中,所有服务都可以根据 sessionId 获取到 Session 数据)了。
关于 Domian 域名:
- 父域:
yunmall.com - 子域:
auth.yunmall.com、order.yunmall.com等
例如认证服务 mall-auth-server 的域 auth.yunmall.com 在发放 Session 时,需要设置 Domain 为父域 yunmall.com。这样浏览器在访问其他微服务时也可以带上此 Cookie,也就可以获取到认证服务存储的 Session 数据了。
在 JavaWeb 原生 API 中指定父域的方式:
1 | new Cookie("JSESSIONID", ".....").setDomain("yunmall.com"); |
下面将介绍如何使用 Spring Session 框架快速实现微服务间的 Session 共享。
Spring Session
Spring Session 是 Spring 的项目之一,它提供了一套创建和管理 Servlet HttpSession 的完美方案。Spring Session 提供了 API 和实现,用于管理用户的 Session 信息。除此之外,它还提供了如下特性:
- 将 session 所保存的状态卸载到特定的外部 session 存储汇总,如 Redis 中,他们能够以独立于应用服务器的方式提供高质量的集群。
- 控制 sessionid 如何在客户端和服务器之间进行交换,这样的话就能很容易地编写 Restful API ,因为它可以从 HTTP 头信息中获取 sessionid ,而不必再依赖于 cookie。
- 在非 Web 请求的处理代码中,能够访问 session 数据,比如在 JMS 消息的处理代码中。
- 支持每个浏览器上使用多个 session,从而能够很容易地构建更加丰富的终端用户体验。
- 当用户使用 WebSocket 发送请求的时候,能够保持 HttpSession 处于活跃状态。
配置与使用
- 导入 Maven 依赖
1 | <!-- 整合 Spring Session --> |
- 配置文件中指定 Session 存储到 Redis 中,并且配置 Redis 信息
1 | spring: |
- 配置 Session 过期时间
1 | server: |
- 在主启动类上添加注解
@EnableRedisHttpSession开启 Spring Session 功能
1 | // 整合 Redis 作为 Session 存储地点 |
- 编写自定义配置类,更改容器中默认的 Spring Session 序列化方式与 Cookie 保存内容。指定存储到 Redis 中序列化方式为 JSON 格式(默认是 JDK 序列化方式),指定 Cookie 中保存的
Domain为父域yunmall.com
1 |
|
如果使用默认的 JDK 序列化方式保存对象,则必须要给要保存的 POJO 实现序列化接口
Serializable
- 向 Session 中存储 POJO
1 |
|
Spring Session 会使用我们自定义的 JSON 序列化器将该对象转换成 JSON 字符串后保存到 Redis 中。同时将该 Session 的 id 以 Cookie 的形式返回给浏览器进行保存。在 Redis 中查看保存结果:
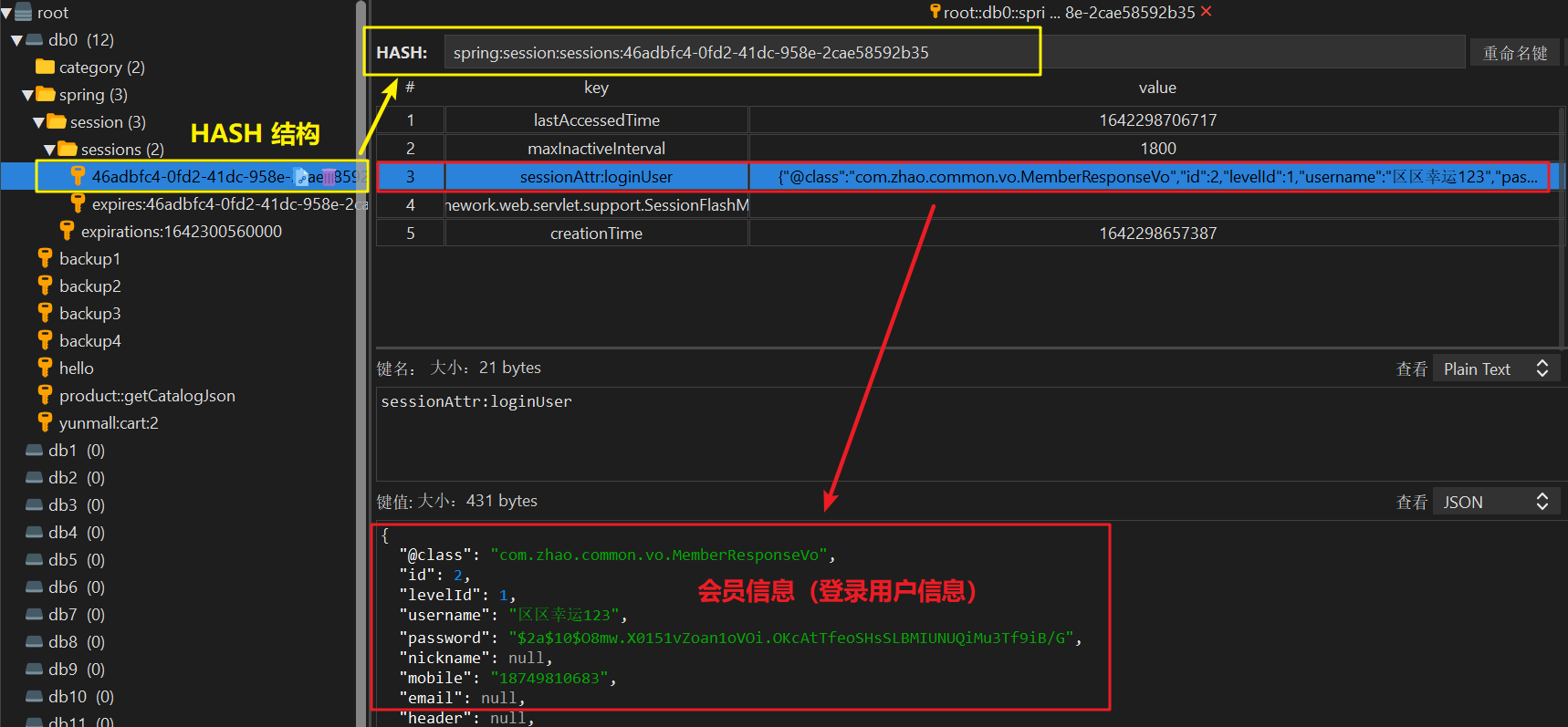
可以看到,POJO 已经成功保存到了 Redis 中,这样其他微服务同样可以在进行上述配置也访问到该数据(其他想访问到 Redis 中 Session 数据的服务必须也得配置 Spring Session)。
- 该 Session 的 id 信息将以 Cookie 的形式返回给浏览器进行保存,并且保存的 Cookie 的
Domain是父域yunmall.com:

这样在重定向到商品服务 mall-product 的首页时,浏览器会带着该 Cookie 进行访问(因为 Domain 匹配上要访问的 URL 了)。这样就可以根据该 Cookie 里存的 sessionid 去 Redis 中查找出对应的 Session 数据,从而成功访问到认证服务存储的 MemberRespVo 数据,并渲染到页面上:
1 | <li> |
Spring Session 核心原理
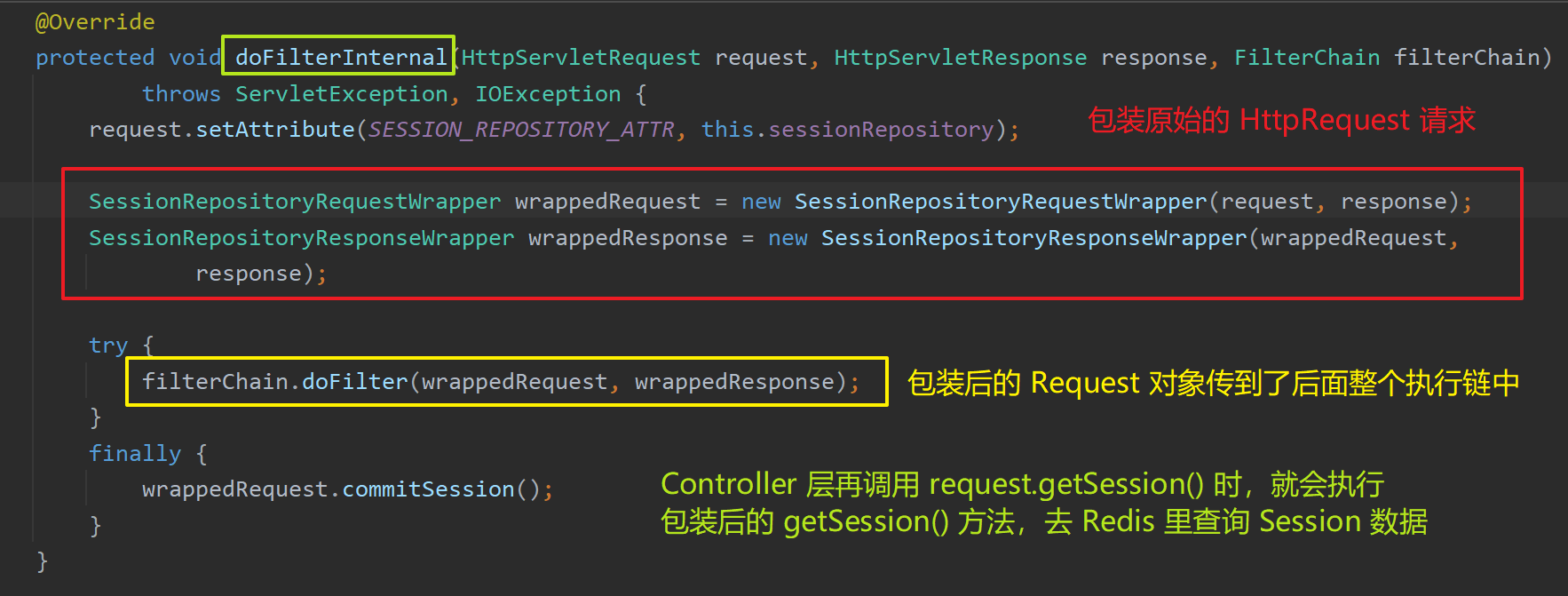
Spring Session 的实现使用了装饰器模式,核心原理是:
- 将普通的
HttpRequest进行了包装,将其包装成了SessionRepositoryRequestWrapper类型的对象 - 并且向容器中注入了一个过滤器
SessionRepositoryFilter,在 Controller 的方法执行前先拦截请求,将原生的HttpRequest包装成了SessionRepositoryRequestWrapper。 - 这样 Controller 层在调用
HttpRequest.getSession()时,真正在执行的就是包装后的SessionRepositoryRequestWrapper的getSession()方法了。 - 根据我们选择的 Redis 配置
RedisHttpSessionConfiguration,该方法的真正执行逻辑是根据 Cookie 中的sessionid去 Redis 里查询该 Session 的真实数据。从而做到了与业务代码的解耦。
过滤器里的代码: