JMM
JMM(Java内存模型:Java Memory Model,简称JMM)本身是一种抽象的概念并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式,它从Java层面定义了主存、工作内存抽象概念。JMM不是Java内存布局,不是所谓的栈、堆、方法区。
JMM关于同步的规定:
- 线程解锁前,必须把共享变量的值刷新回主内存
- 线程加锁前,必须读取主内存的最新值到自己的工作内存
- 加锁解锁是同一把锁
由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间,其实是每个线程缓存在CPU中的高速缓存数据),工作内存是每个线程的私有数据区域,而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问,但线程对变量的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝到自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作主内存中的变量,各个线程中的工作内存中存储着主内存中的变量副本拷贝,因此不同的线程间无法访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成,其简要访问过程如下图:
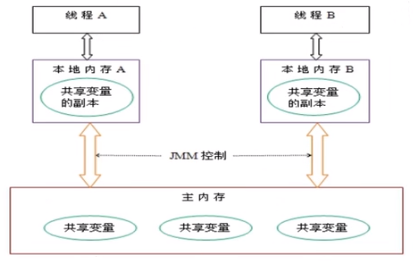
主存就是内存。工作内存指每个线程缓存在CPU中的数据(高速缓存),每个线程都在自己的CPU核心中缓存代码数据,通过总线嗅探得知主存中自己之前缓存的数据值已经过期,从而从主存中获取更新自己缓存中的数据
每个Java线程都有自己的工作内存。操作数据时,首先从主内存中读,得到一份拷贝,操作完毕后再写回到主内存。
JMM可能带来可见性、原子性和有序性问题。所谓可见性,就是某个线程对主内存内容的更改,应该立刻通知到其它线程。原子性是指一个操作是不可分割的,不能执行到一半,就不执行了。所谓有序性,就是指令是有序的,不会被重排。
- 原子性:保证指令不会受到线程上下文切换的影响
- 可见性:保证指令不会受 cpu 缓存的影响
- 有序性:保证指令不会受 cpu 指令并行优化(指令重排序)的影响
CPU 缓存结构
CPU 缓存结构示意图:
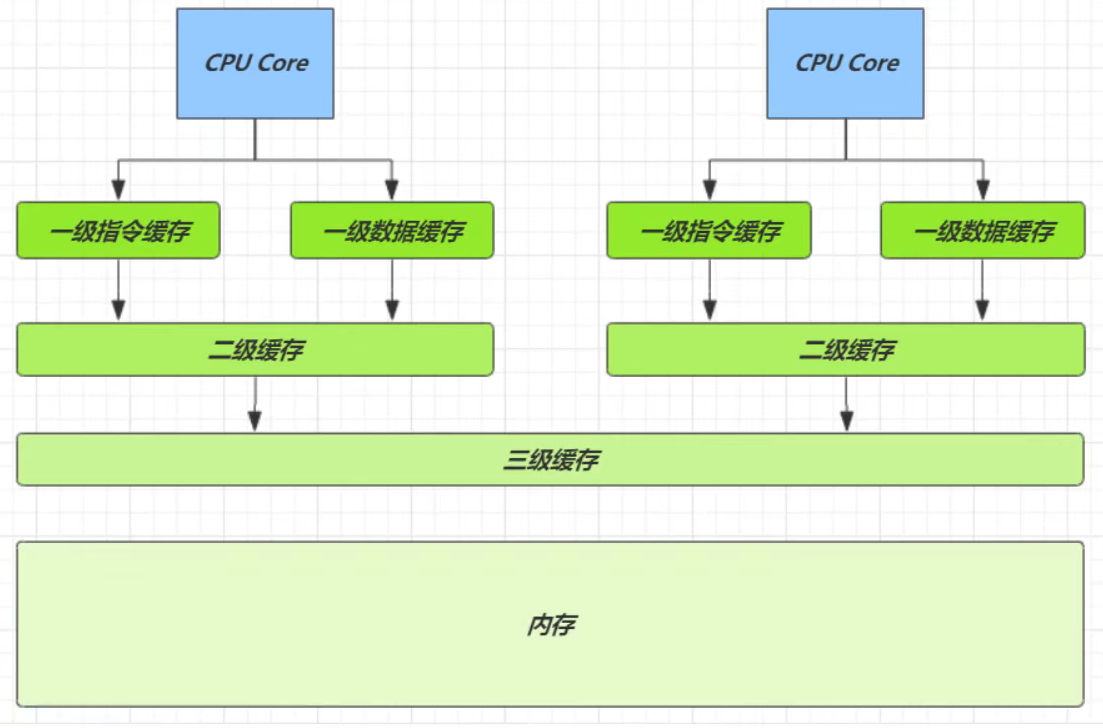
因为 CPU 与 内存的速度差异很大,需要靠预读数据至缓存来提升效率。 而缓存以缓存行为单位,每个缓存行对应着一块内存,一般是 64 byte(8 个 long)。
缓存的加入会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中。CPU 要保证数据的一致性,如果某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效(通过MESI 协议察觉)。
一旦某个缓存行内的数据不是最新的了(通过 MESI 缓存一致性协议,总线嗅探察觉到数据被其他核心锁修改,自己缓存的不再是最新值),就会将该行的缓存数据失效,重新从内存中更新值保存到缓存。
案例
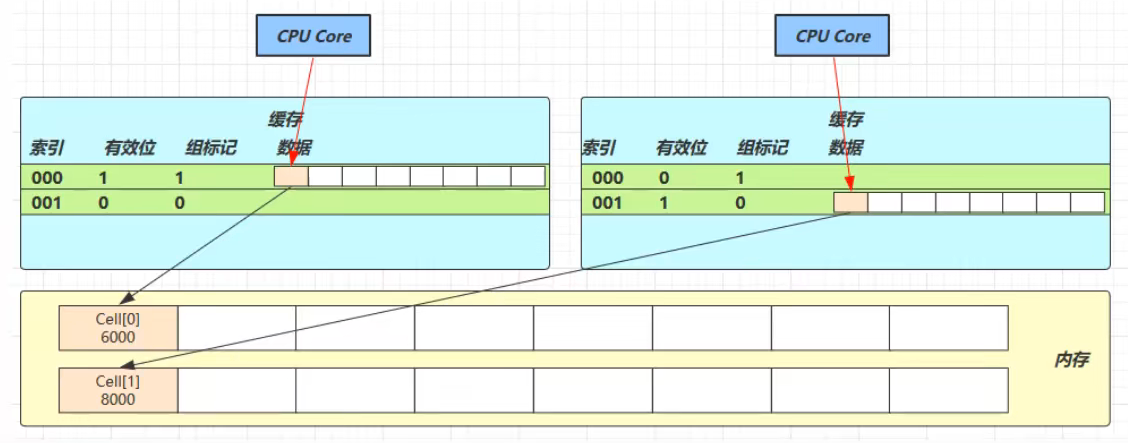
下图中,两个线程分别占用两个 CPU 核心,并且都将内存中的两个数据 Cell[0] 和 Cell[1] 缓存到自己的一个缓存行里(二者保存保存到同一个缓存行里):
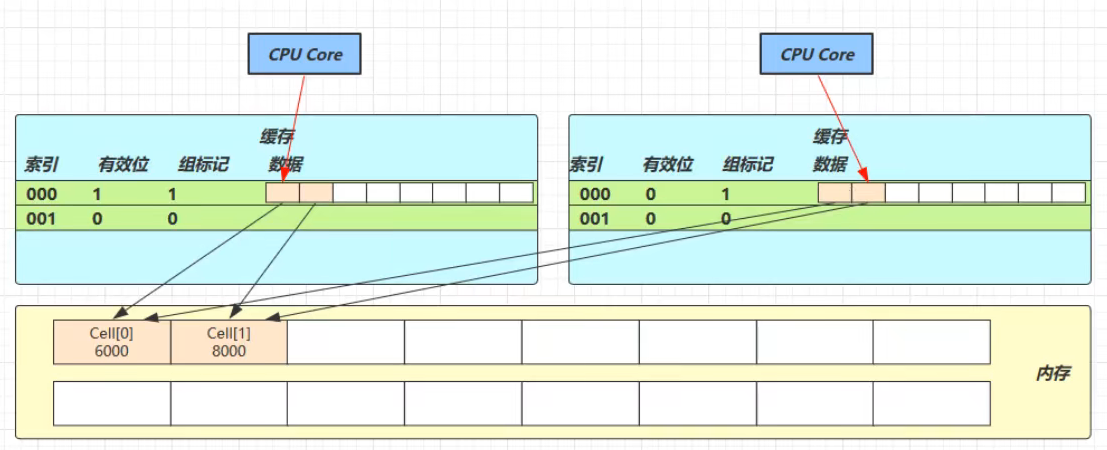
图中每一行为一个缓存行结构,一般是 64 byte(8 个 long)
因为 Cell 是数组形式,在内存中是连续存储的,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),因此缓存行可以存下 2 个的 Cell 对象。这样问题来了:
- Core-0 要修改
Cell[0]
- Core-1 要修改
Cell[1]
无论谁修改成功,都会导致对方 Core 的缓存行失效,比如 Core-0 中Cell[0]=6000, Cell[1]=8000 要累加 Cell[0]=6001, Cell[1]=8000,这时会让 Core-1 的缓存行失效。
@sun.misc.Contended 注解用来解决这个问题,它的原理是在使用此注解的对象或字段的前后各增加 128 字节大小的 padding,从而让 CPU 将对象预读至缓存时占用不同的缓存行。这样,不会造成对方缓存行的失效:
代码:
1
2
3
4
5
6
7
8
9
10
11
12
|
@sun.misc.Contended
static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long prev, long next) {
return UNSAFE.compareAndSwapLong(this, valueOffset, prev, next);
}
}
|
volatile
volatile:易变的
volatile 是 JVM 提供的轻量级的同步机制(synchronized锁是重量级的同步机制)。它可以用来修饰成员变量和静态成员变量,可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的最新值。其特点:
- 保证可见性(保证共享变量在多个线程操作下的可见性)
- 保证有序性(禁止指令重排)
- 不保证原子性(指令交错导致的原子性问题需要加锁来保证)
volatile 关键字常与 CAS 配合使用:自旋的过程中保证 volatile 修饰的共享变量的值永远是最新的(而非会用高速缓存值)。
原理
volatile 的底层实现原理是内存屏障:Memory Barrier(Memory Fence)
- 对
volatile 修饰的变量的写指令后会加入写屏障
- 对
volatile 修饰的变量的读指令前会加入读屏障
volatile 保证可见性
- 写屏障(sfence)保证:在该屏障之前对共享变量的改动,结果都立即同步到主存当中
- 读屏障(lfence)保证:在该屏障之后对共享变量的读取,加载的都是主存中的最新数据
通过读写屏障,在每次需要用到共享变量时都会保证和主存中的值一致。
其他非 volatile 修饰的共享变量仍然可以使用自己的高速缓存。有 volatile 修饰的共享变量会通过读写屏障保证可见性
volatile 保证有序性
- 写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
- 读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
通过读写屏障,保证读写屏障前后的代码不会被重拍到屏障前后
volatile 无法保证原子性
volatile 无法保证原子性。无法解决高并发下的指令交错问题。仍需要加锁来解决。
synchronized
使用 synchronized 关键字能同时满足上面三个特性。在JMM中,synchronized 规定,线程在加锁时:
- 先清空自己工作内存的缓存
- 然后在主内存中拷贝最新变量的副本到自己的工作内存告诉缓存
- 执行再完代码将更改后的共享变量的值刷新到主内存中
- 释放 Monitor 锁
- 其他工作线程通过总线嗅探发现自己之前缓存的值发生变化,就会重新从主内存拉取变量的最新值
总结:添加了 synchronized 关键字后,其所在线程就会强制从主存中更新当前线程所需的成员变量值到自己的高速缓存中,从而保证了可见性。
注意:synchronized 包裹的代码块内仍然可能出现指令重排序。其保证有序性的方式是通过保证原子性实现的。只要共享变量能在代码块内被完整保护,那么因为其原子性的特点,就能保证及时指令重排序了,也能保证是有序性的。因为其他线程都进不来,并且共享变量是被完全保护住的,所以就间接保证了有序性。