Docker 简介
Docker 理念
Docker 是基于Go语言实现的云开源项目。Docker 的主要目标是“Build, Ship[ and Run Any App,Anywhere",也就是通过对应用组件的封装、分发、部署、运行等生命期的管理,使用户的APP (可以是一个WEB应用或数据库应用等等)及其运行环境能够做到“一次封装,到处运行”。

Linux容器技术的出现就解决了这样一一个问题,而Docker就是在它的基础上发展过来的。将应用运行在Docker容器上面,而Docker容器在任何操作系统上都是一致的,这就实现了跨平台、跨服务器。只需要一次配置好环境,换到别的机器上就可以一键部署好,大大简化了操作。
一句话:Docker 是解决了运行环境和配置问题的软件容器,方便做持续集成并有助于整体发布的容器虚拟化技术
之前的虚拟机技术
虚拟机(virtual machine)就是带环境安装的一种解决方案。
它可以在一种操作系统里面运行另一种作系统,比如在Windows系统里面运行Linux系统。应用程序对此毫无感知,因为虚拟机看上去跟真实系统一模一样,而对于底层系统来说,虚拟机就是一个普通文件,不需要了就删掉,对其他部分毫无影响。这类虚拟机完美的运行了另一套系统,能够使应用程序,操作系统和硬件三者之间的逻辑不变。
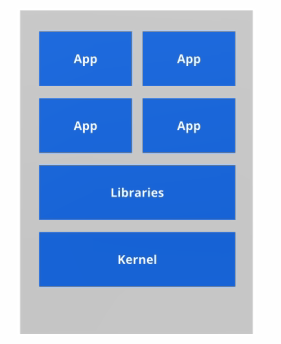
虚拟机的缺点:
容器虚拟化技术
由于前面虛拟机存在这些缺点,Linux 发展出了另一种虚拟化技术: Linux 容器(Linux Containers,缩为LXC)。
Linux 容器不是模拟一个完整的操作系统,而是对进程进行隔离。有了容器,就可以将软件运行所的所有资源打包到一个隔离的容器中。容器与虚拟机不同,不需要捆绑一整套操作系统,只需要软件工作所需的库资源和设置。系统因此而变得高效轻量并保证部署在任何环境中的软件都能始终如一地运行。
比较Docker和传统虚拟化方式的不同之处:
- 传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程。
- 而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机为轻便。
- 每个容器之间互相隔离,每个容器有自己的文件系统,容器之间进程不会相互影响,能区分计算资源。